一、什么是链表
链表是一种数据结构,跟数组不同,链表不需要连续的内存空间,而是通过指针将零散的内存块连接起来。
因此,链表的查找需要通过节点按顺序遍历,而增加与删除通过只需要操作指针指向,这也造成了相比数组,链表的查找性能消耗大而增加和删除消耗小的特点。
链表由节点组成,一般每个节点最少包含用于储存数据的data区和用于指向下一个节点的指针next,有的链表可能会有头结点或尾结点用于存储链表长度等信息。

二、链表的简单实现
先来实现一个简单的节点类:
1 | /** |
1.插入节点
1.1不按照排序的插入
1 | /** |
1.2按照排序插入
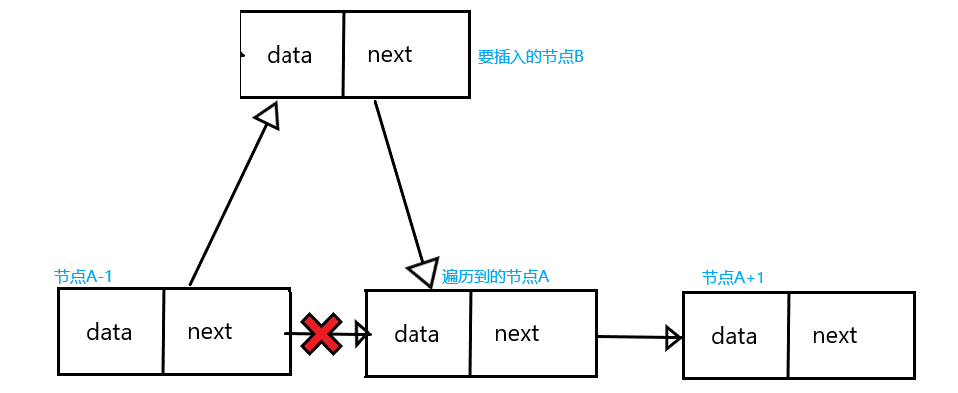
要想按顺序插入节点,需要确定节点的位置,也就是确定新节点的大小,以图为例:
遍历链表,我们把遍历到的节点叫A,A之前的节点叫A-1,A之后的节点叫A+1,要插入的节点叫B,有以下几种情况:
- 当A的序号大于B时,就把B插到A前,也就是原本的A和A-1之间
- 当A的序号等于B时,抛出异常禁止插入
- 当A的序号小于B时,就跳过这个节点,继续遍历,然后对比A+1和B的大小
- 当A就是链表最后一个节点时,A还是小于B,那就直接让B插到A后,变成链表的尾节点
按这个思路,我们在原来的类里新增一个方法:
1 | /** |
2.查找节点
1 | /** |
3.修改节点
修改节点与按顺序插入逻辑相似,需要先遍历并找到要修改的节点,然后用新节点去替换旧节点,或者干脆直接修改节点内的信息
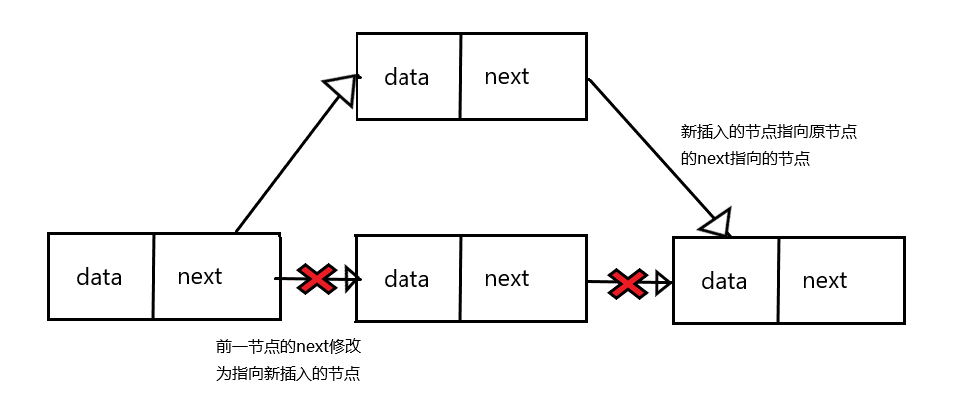
1 | /** |
4.删除节点
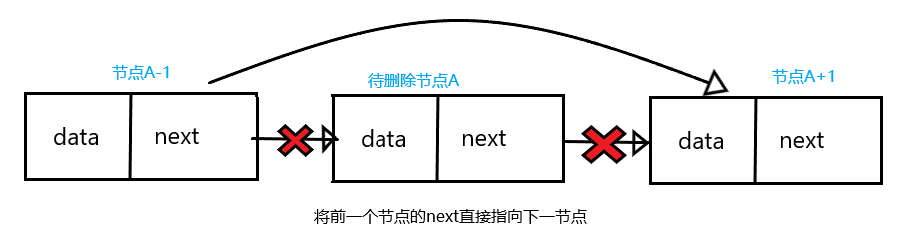
因为在单向链表中,节点无法知道自己前一个节点的情况,以图为例:
如果我们想要删除节点A,那么就要找到A的前一个节点A-1,根据是否存在A后的节点A+1有以下几种情况:
A节点就是链表尾节点,此时只需让A-1节点的next指向null即可
nodeA-1.next = nullA节点后有A+1,此时让A-1节点指向A+1节点
nodeA-1.next = nodeA-1.next.next
按这个思路,在类里新加一个方法:
1 | /** |
三、完整实现代码
1 | /** |
四、环形链表
循环链表是一种特殊单链表,他跟单链表的区别在于尾节点的尾指针指向了链表的头结点,也就是相当于将链表连接成了一个环形。
环形链表可以用于处理能描述为环形的数据,典型的比如约瑟夫问题。
