一、双向链表
双向链表与单链表基本相似,但是最大的区别在于双向链表在节点中除了指向下一节点的next指针外,还有指向前一节点的prev指针,这使得双向链表在可以在任意节点从头尾两个方向进行遍历,是“双向”的。
和单链表相比,双向链表在删除和查询等方面明显在操作上更具有灵活性,但是会消耗更多的内存,需要根据使用条件进行取舍。
java中的LinkedHashMap的本质即是一个双向链表。
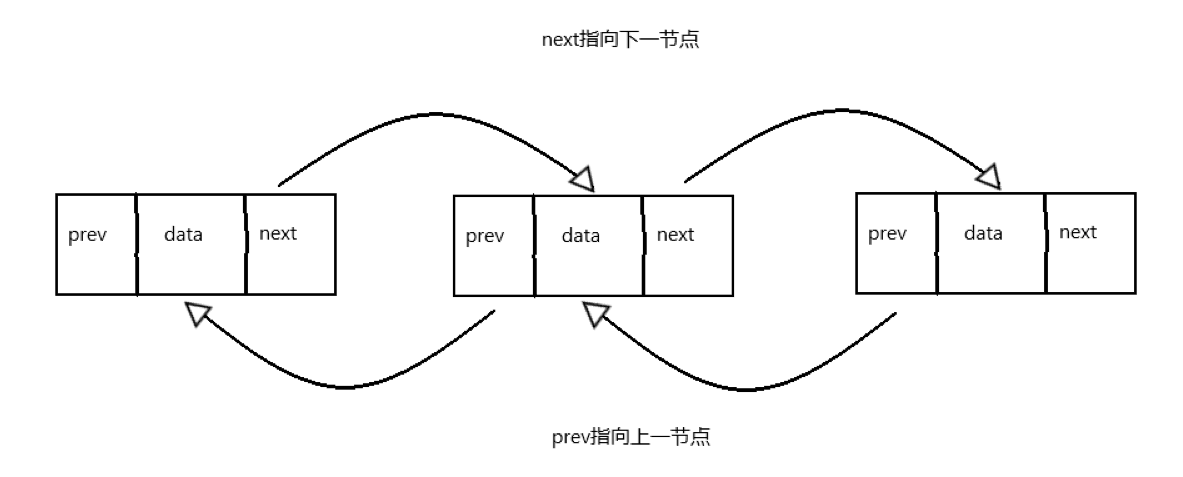
二、双向链表的简单实现
修改原来的Node类,在里面添加一个新成员变量Node prev
1 | /** |
1.添加
添加与单向链表代码逻辑一样,但是新节点在添加时需要修改prev指针指向原来的尾节点。
举个例子,对于无排序插入,原本有节点A,现在要插入一个B:
- 找到A,然后让
A.next指向B - 让
B.prev指向A
而对于排序插入,就是原有节点A,C,要在中间插入B:
- 找到A,让
B.prev指向A - 让
B.next指向A.next,也就是让B的next指向C - 让
A.next.prev指向B,也就是让C的prev指向B - 让
A.next指向B
1 | /** |
2.删除
由于相对单链表,双向链表的节点可以自己找到上一节点,所以删除的时候可以直接找到要删除的节点进行操作。
举个例子,假设有节点A,B,C,现在要删除B:
- 找到B,让
B.prev.next=B.next,也就是让A的next指向C - 让
B.next.prev=B.prev,也就是让C的prev指向A
如果要删除的节点已经是尾节点了,那就跟单链表一样了。
1 | /** |
3.修改,查询(与单链表一致)
由于修改和查询与单链表基本一致,这里就不在赘述了,直接放代码:
1 | /** |