此文为极客时间:MySQL实战45讲的 21、30、40节锁相关部分的总结
间隙锁的加锁原则
间隙锁加锁的情况,包含了两个“原则”、两个“优化”和一个“bug”。
- 原则 1:加锁的基本单位是 next-key lock。即间隙锁+行锁(前开后闭区间)。
- 原则 2:查找过程中访问到的对象才会加锁。
- 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
- 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
以下面的表为例:
1 | CREATE TABLE `t` ( |
我们需要注意一下,c 是加了索引的,而 d 没有。直观点就是下图:
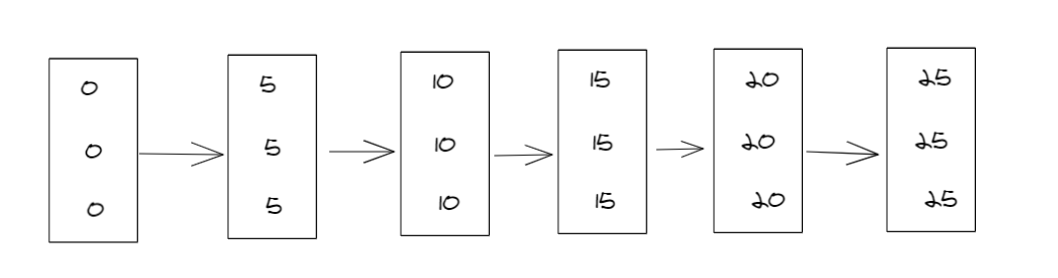
一.唯一索引等值查询间隙锁

由于表 t 中没有 id=7 的记录,所以用我们上面提到的加锁规则判断一下的话:
- 根据原则 1,加锁单位是 next-key lock,session A 加锁范围就是 (5,10];
- 同时根据优化 2,这是一个等值查询 (id=7),而 id=10 不满足查询条件,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10)。
所以,session B 要往这个间隙里面插入 id=8 的记录会被锁住,但是 session C 修改 id=10 这行是可以的。
二.非唯一索引等值查询间隙锁
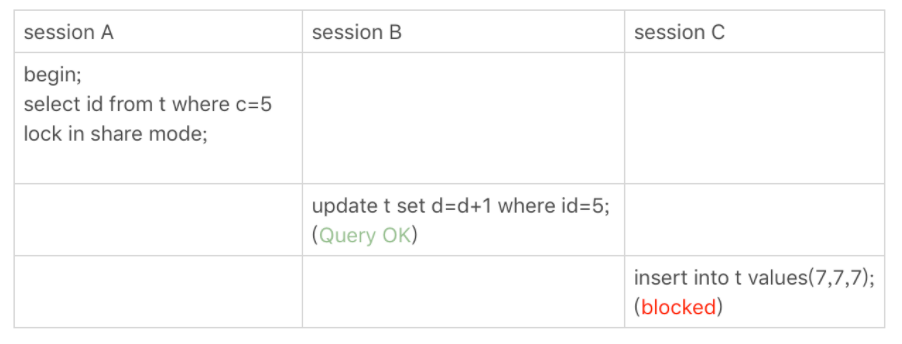
我们分析一下这个过程:
- 首先,根据原则1,会为(0,5] 范围加上 next-key lock;
- 由于 c 是普通索引,所以因此查到5以后不会停下,会向右遍历到第一个不符合条件的值,也就是10以后才会停下。所以锁的范围会扩张到(0,10];
- 由于符合优化2,所以 next-key lock 会退化为间隙锁,也就是会变成(0,10);
- 根据原则2,只有访问到的才加锁,也就是锁只加在c字段上,对主键索引是没关系的,所以 sessionB 可以更新成功。但 session C 要插入一个 (7,7,7) 的记录,就会被 session A 的间隙锁 (5,10) 锁住。
需要注意,在这个例子中,lock in share mode 只锁覆盖索引,但是如果是 for update 就不一样了。 执行 for update 时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。
这个例子说明,锁是加在索引上的;同时,它给我们的指导是,如果你要用 lock in share mode 来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段。比如,将 session A 的查询语句改成 select d from t where c=5 lock in share mode。
三.唯一索引范围锁
假如现在有两条 sql:
1 | select * from t where id=10 for update; |
在逻辑上,两条 sql 是等价的,但是加锁的情况是不一样的。以第二条 sql 为例:

- 首先加了一个范围为 (5,10] 的 next-key lock,由于id 是唯一索引,根据优化1锁会退化为行锁,也就是只锁id=10;
- 由于是范围查找,会继续向右遍历,找到id=15的行发现第一条不符合 id<10 的数据,然后加上(10,15]的锁。
也就是说,最终 sessionA 会加上 [10,15] 的锁。
需要注意一点,首次 session A 定位查找 id=10 的行的时候,是当做等值查询来判断的,而向右扫描到 id=15 的时候,用的是范围查询判断。也就是说,>= 这个查询,实际上是等值+范围查询,两次锁的分别加上的。
四.非唯一索引范围锁
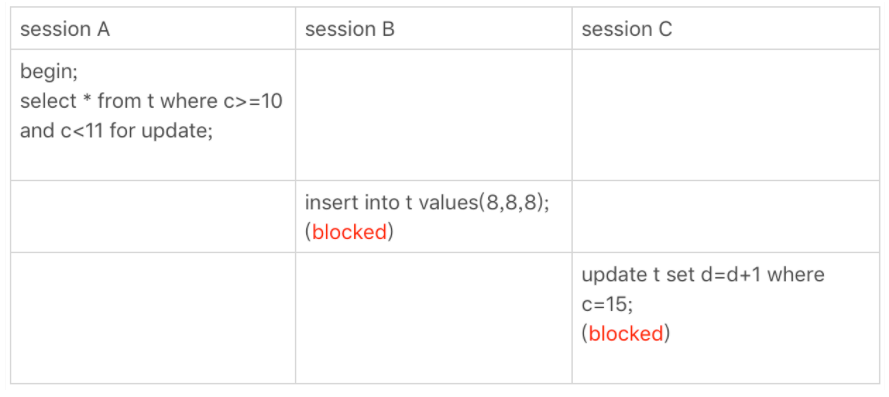
- 首先,由于 c>=10 满足的第一条数据就是 c=10 的这行,因此会加上(5,10] 的 next-key lock,由于 c 不是唯一索引,所以不符合优化1的条件,所以最终加锁范围还是(5,10]
- 由于是范围查找,继续向右遍历,直到找到第一行不符合 c<11 的数据,也就是 c=15 这行,加上(10,15] 的,由于后半段是范围查询,所以不符合优化2的条件,所以最终加锁范围还是(10,15]
也就是说,最终 sessionA 会加上 (5,15] 的锁。
五.唯一索引范围锁 bug
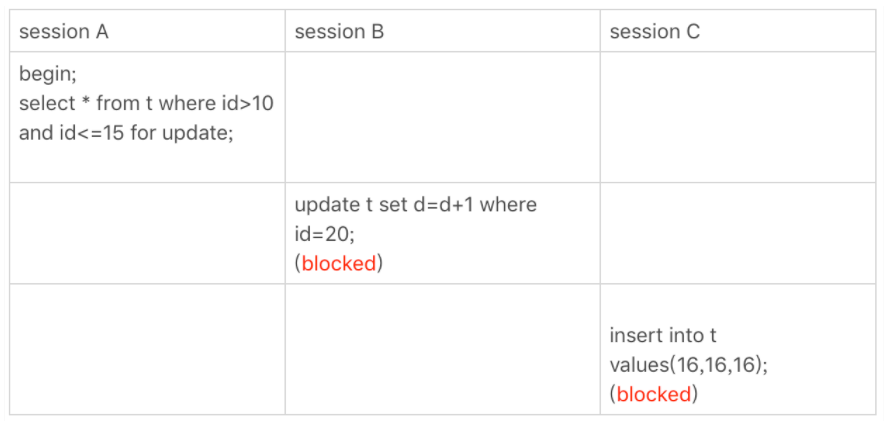
session A 是一个范围查询,按照原则 1 的话,应该是索引 id 加上 (10,15] 这个 next-key lock。并且因为 id 是唯一键,相比于情况三,id = 15的这条数据是存在的,所以循环判断到 id=15 这一行就应该停止了。
但是实现上,InnoDB 会往前扫描到第一个不满足条件的行为止,也就是 id=20。而且由于这是个范围扫描,因此索引 id 上的 (15,20] 这个 next-key lock 也会被锁上。
六.两个相同的非唯一索引上的等值查询
1.不加limit的情况
现在已经有了(10,10,10)这条数据,再插入(30,10,30),也就是说,现在有两条 c = 10 的数据。但是由于非唯一索引上包含主键的值,所以两种是不可能完全相同的,这两条数据也有间隙。
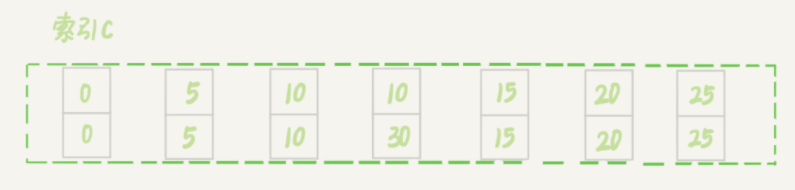
在上图的状态,执行sql:
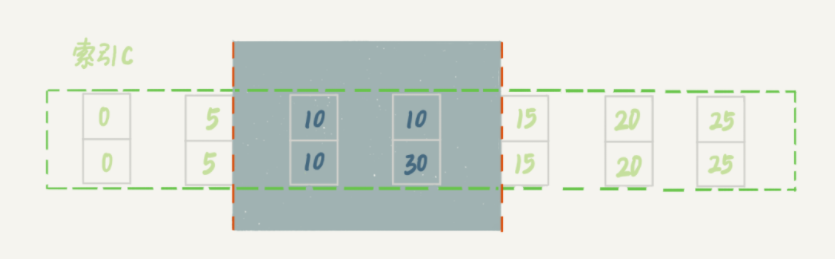
- 先找到第一条 c=10 的数据,也就是 id=10 的这行,加上(5,10] 的锁;
- 向右遍历,一直到第一个不符合条件的数据,也就是加上(10,15] 的锁。注意,这里指的是id,也就是现在这个区间的锁包含了id为(30,15,20)这三条数据和他们的间隙。由于这是等值查询,根据优化1,会退化为间隙锁,也就是变成(10,15);
也就是说,现在加锁的就会变成:
2.加limit限制的情况
现在,在上文的 delete 的情况加上 limit:

加锁的逻辑会有一点变化:
- 依然先加(5,10] 的锁;
- 向右遍历找到第二条符合条件的数据,即 id=30 的数据。由于加上了 limit ,已经找到两条了,所以就不必向后再找到一条不符合的数据了,也就不需要加上(30,15)的锁了。
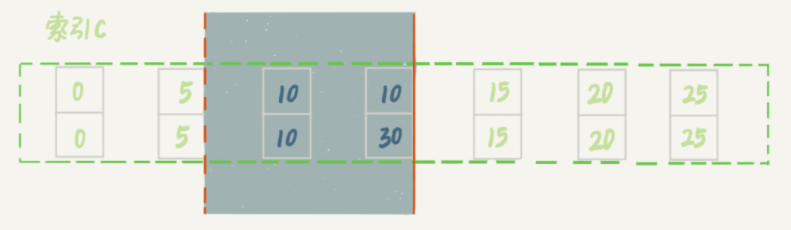
可以看见,这样做减少了锁的范围。
这个例子对我们实践的指导意义就是,在删除数据的时候尽量加 limit。这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围。
七、间隙锁的扩大
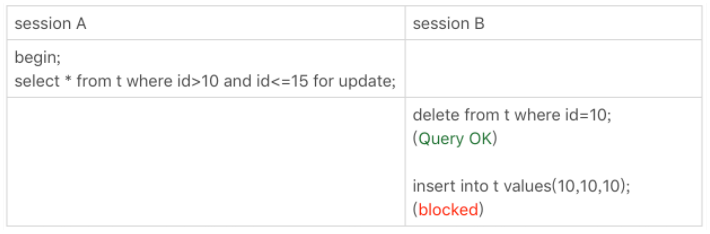
我们来分析一下:
- 由于 id <= 15 第一条满足的数据就是 id=15 这条数据,因此加上 (10,15] 的锁,因为 id > 10,所以不必再理id=10之前的数据了。由于是一个等值查询,所以(10,15] 退化为间隙锁(10,15);
- sessionB 删除了 id=10 这行数据,由于没锁到 id=10,所以顺利删除了该数据;
- 由于缺少了10,所以原本(10,15)的间隙锁扩大为(5,15),因此插入语句被阻塞。
类似的例子还有这个:

- sessionA 加上了 ( 5,supremum] 的锁;
- sessionB 将 c=5 变成了 c=1,现在锁扩大到了(1,supremum];
- sessionB 试图将 c=5 变成 c=1,此时c=5已经在锁的范围了,因此更新的sql被堵塞。
八、总结
分析间隙锁的加锁原则:两个原则,两个优化,一个bug。
加锁的对象一般来说是索引,也就是说,只要更新使用的索引跟上锁的索引不一样,就不会影响到插入间隙的行为。除非使用 for update,这会为整段数据都加上锁。
加锁单位是 next-key lock,即间隙锁+行锁,是一个前开后闭的区间。也就是,访问到了A,那么锁就是(A-1,A],即实际上加锁范围由间隙右边的节点决定。
有且仅在等值查询的过程,对于唯一索引,锁有可能退化为行锁也可能退化为间隙锁;但是对于非唯一索引,锁只可能退化为间隙锁。
如果删除了间隙锁的“边界”,会导致间隙锁的扩大。
对于唯一索引:
- 等值查询:先加本段的 next-key lock,即前面一段间隙锁加本行行锁。如果本行即使要查询的数据,就退化为行锁,否则就退化为间隙锁。
- 范围查询:同上,但是必然会向后查找到第一个不符合的数据,先加上后半段的 next-key lock,再退化为间隙锁。
对于非唯一索引:
- 等值查询:先加本段的 next-key lock,不管要查找的值存不存在,必在查找值的基础上向后找到第一条不符合的数据,加上 next-key lock,再让后半段锁退化为间隙锁。
- 范围查询:同上,由于不是等值查询所以不符合优化2的条件,相比等值查询,他的后半段还是 next-key lock 而不会退化为间隙锁。
- 多个重复的索引值,不加 limit:可以看成特殊的范围查询,会把第一个索引位置的前半段加上 next-key lock,然后再为第一到最后一个索引位置的这段区域全加上 next-key lock,最后再向后查找到第一个不符合条件的值,并加上 next-key lock,由于也算等值查询,根据优化2后半段从 next-key lock退化为间隙锁。
- 多个重复的索引值,加 limit:同上,但是由于加了条数限制,所以不必再向后查找到第一个不符合条件的值,所以相比不加 limit 少加最后一个索引位置的之后的一段间隙锁。