一、什么是赫夫曼编码
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,
使用赫夫曼编码可以有效的压缩数据,通常可以节省20%~90%的空间。
在理解赫夫曼编码前,我们需要对通讯领域的两种编码方式有个粗略的了解。
假设我们需要传输 I'm a jvav programmer and I love programming这样一句话,我们有两种传输方式:
定长编码
直接转换为对应长度的二进制格式
1
01101111 00100000 00100000 00100000 00100111 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100111 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000 00100000
总长度为296个字符
变长编码
按照各个字符出现的次数进行编码,按出现次数编码,出现次数越多的,则编码越小:
比如空格出现最多次,然后是a,以此类推......
1
0= ,1=a,10=i,11=o......
当传输的信息越多的时候,变长编码实际传输的长度相对定长编码就越小
另外,我们还需要了解一下什么是补码:
计算机里面只有加法器,没有减法器,所以减法必须用加法来完成。 对于 100 以内的十进制数,“-1”就可以用"+99"代替。比如 25 - 1 = 24,可以写成 25 + 99 = (1)24。 如果限定了两位数,那“-1”和“+99”就是等效的。同样,“-2”可以用“+98”代替。
它们之间,称为补数,而100就称为模。
对于8位二进制数:0000 0000~1111 1111(255),模为256。 -1,可以用 +255(1111 1111)代替。 -2,可以用 +254(1111 1110)代替
这些二进制数,就称为负数的补码
二、赫夫曼编码思路
同样举个例子,我们要传输 i like like like java do you like a java这段话
统计各字符的出现次数
1
d:1 y:1 u:1 j:2 v:2 o:2 l:4 k:4 e:4 i:5 a:5 :9
将字符出现次数作为节点的权,构建一个赫夫曼树(这里步骤同上一篇文章)
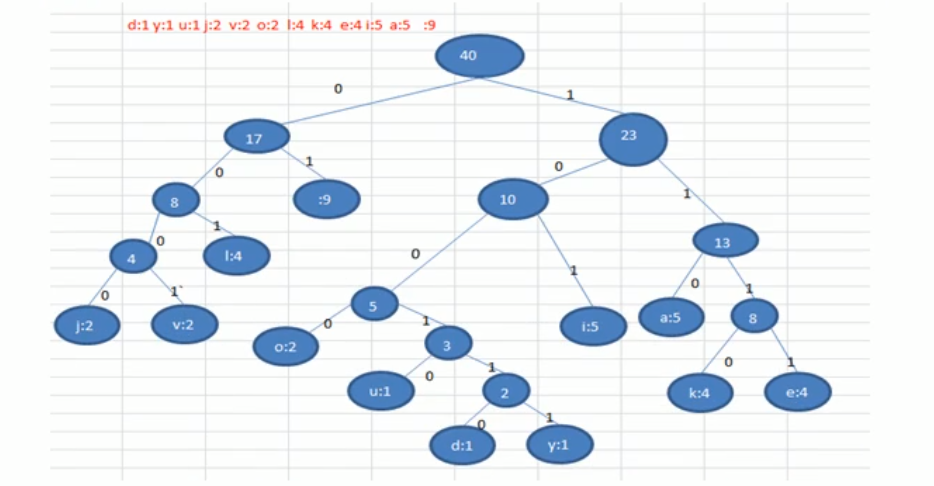
我们使用0和1来描述某个节点在树中往左或往右的路径,比如j,从根节点出发抵达j的路径就是0000,抵达i的路径就是101
于是现在对所有字符的路径进行统计,就有:
1
2o: 1000 u: 10010 d: 100110 y: 100111 i: 101 a : 110
k: 1110 e: 1111 j: 0000 v: 0001 l: 001 : 01按照上面的路径,我们将其转为二进制
1
1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100110111101111011100100001100001110
直接转为二进制长度为359,而经过赫夫曼编码长度则是133,与直接转为二进制相比,缩短了62.9%
三、代码实现
1.创建节点类
1 | /** |
2.统计字符出现次数,并组装节点列表
对应思路中的第一步:
1 | /** |
3.生成赫夫曼树
对应思路中的第二步:
1 | /** |
当然,这个时候可以通过前序遍历来检查是否构建成功
1 | /** |
4.得到赫夫曼编码
对应思路中的第三步:
我们已经得到了赫夫曼树,现在我们需要获得从根节点到各个叶子结点的路径,也就是赫夫曼编码
1 | /** |
5.将得到的赫夫曼编码转回字节数组
对应思路中的第四步,也就是最后一步:
我们得到了赫夫曼编码表,也就是这玩意: Map<Byte, String> huffmanCodes,每串赫夫曼编码字符串都对应一个字符,我们需要处理赫夫曼编码的每一个字符,将其转为二进制后再转为byte,最后处理完得到一队字节数组。
1 | /** |
6.解码
信息被赫夫曼编码处理后我们会得到一队字节数组,如果要解码,我们需要先把字节数组按字符一个字节一个字节的转为二进制,然后通过赫夫曼编码表把二进制和字符字节一一找出:
1 | /** |
四、完整代码
具体代码和测试用例可以去GitHub上看,这里就放实现类:
1 | import java.util.*; |