一、什么是图
1.概述
首先,我们已经在之前学习过了树这种数据结构,树能反映一对多的关系,但是却无法反映多对多的关系,因此我们引入了图这种数据结构。
对于图,其节点也可以叫做顶点,每个节点具有零或者多个相连节点,每个节点之间的连接称为边,从一个节点到达另一个节点路线都称为路径。
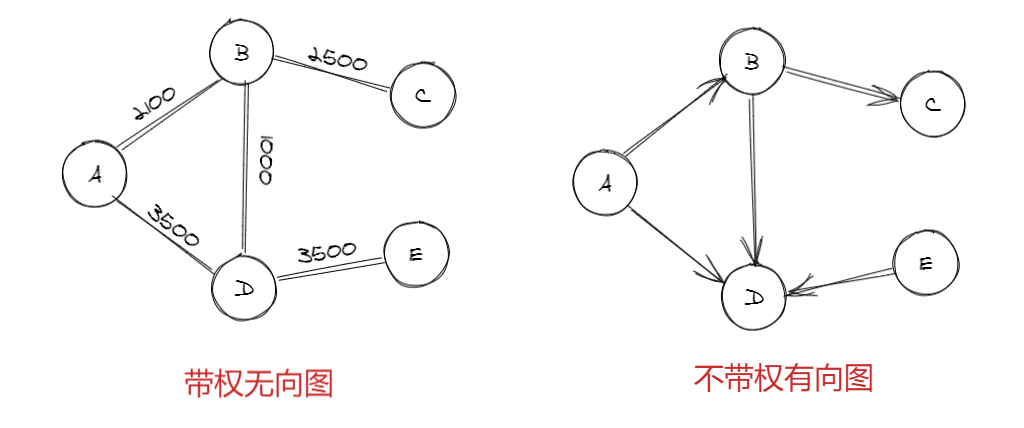
以上图为例,其中:
- 无向图:顶点之间连接没有方向。比如从A到C,可是A -> B -> C,也可以是A -> D -> B -> C。
- 有向图:顶点之间连接有方向。如果A到B,必须是A -> B,不能是B -> A
- 带权图:边带有权值。
2.树与图的关系
实际上,对于有向图还分为两种情况,即图中含环或者图中不含环的单向图,其中含环的图可以从某个顶点出发最终返回原点。
结合对图的定义,我们不难发现,树也可以理解为不含有环的单向图,是图的子集。
两者的区别在于:
- 图中每个节点可以有任意数量的边,而树两个节点间仅仅只有一条边
- 图没有根节点,而树有
- 图中可以存着环,而树不行
- 如果有n个节点,图最多有n*(n-1)条边,而树最多有n-1条边
二、图的表示与构建
图的表示就是边与边关系的表示,有二维数组(邻接矩阵)和链表(邻接表)两种表示方法。
1.邻接矩阵
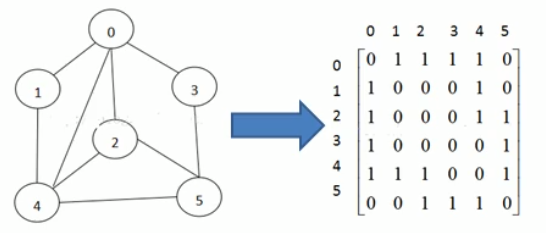
我们建立一个二维数组(矩阵),第一维表示顶点,而第二维表示与该顶点相连接的点。
比如说0号点与1,2,3,4相连,与0(自己)和5不相连,表示为[0][011110],其中,二维数组中的1表示与0号点相连,0表示与0号点不相连
2.邻接表
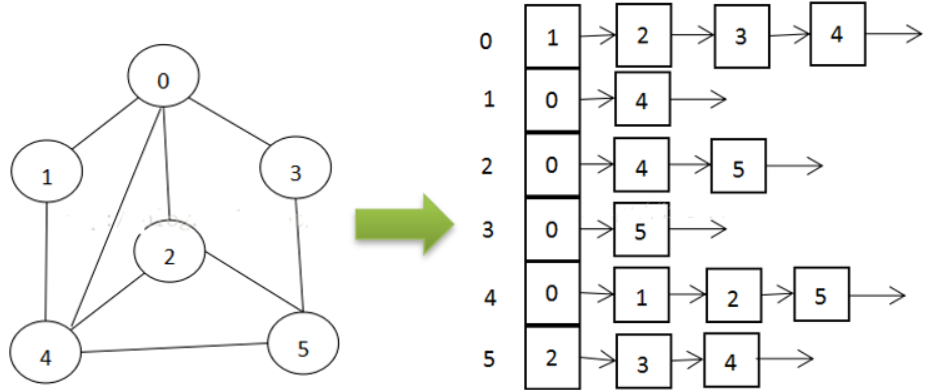
邻接表相比邻接矩阵,只表示关联的边而不表示不关联的表,相对邻接矩阵而言更简洁也更节省空间
3.代码实现
我们使用邻接矩阵的方式来示范如何使用代码构建一个图。
为了方便理解,我们使用两个数组来表示节点与节点之间的对应关系:
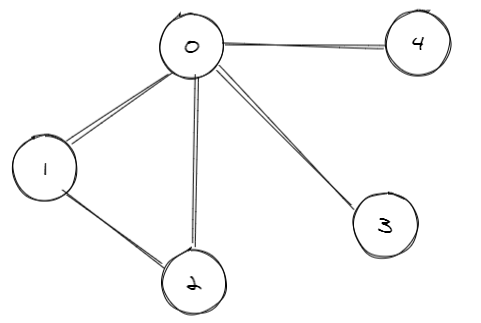
如上图,上图的节点之间的对应关系通过两个数组来表示就是{0,0,0,0,1} -> {1,2,3,4,2},即 0->1,0->2,,0->3,,0->4,,1->2,可见要创建的图有5个节点。
对应实现代码如下:
1 | /** |
三、图的深度优先搜索
图的遍历有两种策略:深度优先搜索(DFS)和广度优先搜索(BFS)。
以下的演示我们仍基于第二部分创建的图为示例:

1.思路分析
dfs的搜索大体思路是这样的:
首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点,然后重复以上步骤直到完成遍历。
这个思路如果学过树的遍历会感觉非常熟悉。由前面知道,树就是一种特殊的图,所以树的前、中、后序遍历其实就是树的dfs。
2.代码实现
将思路转换为代码实现的步骤:
- 访问第一个节点v,并且将其标记为已访问
- 查找第一个节点的邻接节点w:
- 如果w节点不存在,则继续查找v的下一个邻接节点
- 如果w存在,并且未访问,则将w当成下一个v,进行递归
第一步,我们需要在Graph类中添加isVisted公共变量用于标记节点是否被访问:
1 | //记录节点是否被访问 |
第二步,我们需要查找节点是否存在相连节点方法
1 | /** |
第三步,借助访问标记和查找邻接节点方法实现dfs
1 | /** |
四、图的广度优先搜索
1.思路分析
bfs的大题思路是这样的:
首先创建一个队列,把第一个邻接节点入队,然后队列元素出队,把该元素的邻接节点入队,然后出队.....重复该步骤,一层一层的遍历同级节点
如果我们按这个思路,将4作为起始节点,那么第一个4入队,然后4出队,把4的邻接节点0入队,接着0出队,把0的邻接节点1,2,3,入队;同理如果将0作为起始节点,那么第一次0入队,然后0出队,把0的邻接节点1,2,3入队......
2.代码实现
将思路转换为代码实现的步骤:
- 访问初始节点v,标记并入队
- 当队列不为空时,将队头节点u出队,否则跳过本次循环
- 查找u的第一个邻接节点w,如果不存在就重复步骤2,否则:
- 若w未被访问,则标记并入队
- 查找u继w后的下一个邻接节点,重复步骤3
这里继续复用上文dfs中使用的 getNeighbor()、getNextNeighbor()和 isVisted[]
1 | /** |
值得一提是,虽然上文的例子不太直观,但是bfs也常常用于树的层次遍历,比如
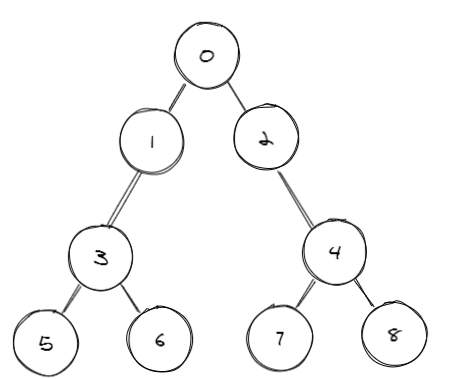
1 | //测试数据 |
可以很明显的看出,是一层一层遍历的,这也很直观的反应了bfs的执行逻辑。