概述
ArrayList 是 List 接口下一个基于可扩展数组的实现类,它和它的兄弟类 Vector 有着一样的继承关系,也都能随机访问,但是不同的是不能保证线程安全。
这是关于 java 集合类源码的第三篇文章。往期文章:
一、ArrayList 的类关系
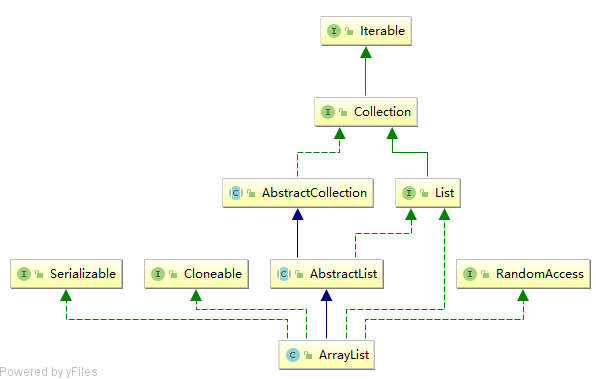
ArrayList 实现了三个接口,继承了一个抽象类,其中 Serializable ,Cloneable 与 RandomAccess 接口都是用于标记的空接口,他的主要抽象方法来自于 List,一些实现来自于 AbstractList。
1.AbstractList 与 List
ArrayList 实现了 List 接口,是 List 接口的实现类之一,他通过继承抽象类 AbstractList 获得的大部分方法的实现。
比较特别的是,理论上父类 AbstractList 已经实现类 AbstractList 接口,那么理论上 ArrayList 就已经可以通过父类获取 List 中的抽象方法了,不必再去实现 List 接口。
网上关于这个问题的答案众说纷纭,有说是为了通过共同的接口便于实现 JDK 代理,也有说是为了代码规范性与可读性的,在 Stack Overflow 上 Why does LinkedHashSet extend HashSet and implement Set 一个据说问过原作者的老哥给出了一个 it was a mistake 的回答,但是这似乎不足以解释为什么几乎所有的容器类都有类似的行为。事实到底是怎么回事,也许只有真正的原作者知道了。
2.RandomAccess
RandomAccess 是一个标记性的接口,实现了此接口的集合是允许被随机访问的。
根据 JavaDoc 的说法,如果一个类实现了此接口,那么:
1 | for (int i=0, n=list.size(); i < n; i++) |
要快于
1 | for (Iterator i=list.iterator(); i.hasNext(); ) |
随机访问其实就是根据下标访问,以 LinkedList 和 ArrayList 为例,LinkedList 底层实现是链表,随机访问需要遍历链表,复杂度为 O(n),而 ArrayList 底层实现为数组,随机访问直接通过下标去寻址就行了,复杂度是O(1)。
当我们需要指定迭代的算法的时候,可以通过实现类是否实现了 RandomAccess 接口来选择对应的迭代方式。在一些方法操作集合的方法里(比如 AbstractList 中的 subList),也根据这点做了一些处理。
3.Cloneable
Cloneable 接口表示它的实现类是可以被拷贝的,根据 JavaDoc 的说法:
一个类实现Cloneable接口,以表明该通过Object.clone()方法为该类的实例进行逐域复制是合法的。
在未实现Cloneable接口的实例上调用Object的clone方法会导致抛出CloneNotSupportedException异常。
按照约定,实现此接口的类应使用公共方法重写Object.clone()。
简单的说,如果一个类想要使用Object.clone()方法以实现对象的拷贝,那么这个类需要实现 Cloneable 接口并且重写 Object.clone()方法。值得一提的是,Object.clone()默认提供的拷贝是浅拷贝,浅拷贝实际上没有拷贝并且创建一个新的实例,通过浅拷贝获得的对象变量其实还是指针,指向的还是原来那个内存地址。深拷贝的方法需要我们自己提供。
4.Serializable
Serializable 接口也是一个标记性接口,他表明实现类是可以被序列化与反序列化的。
这里提一下序列化的概念。
序列化是指把一个 Java 对象变成二进制内容的过程,本质上就是把对象转为一个 byte[] 数组,反序列化同理。
当一个 java 对象序列化以后,就可以得到的 byte[] 保存到文件中,或者把 byte[] 通过网络传输到远程,这样就相当于把 Java 对象存储到文件或者通过网络传输出去了。
值得一提的是,针对一些不希望被存储到文件,或者以字节流的形式被传输的私密信息,java 提供了 transient 关键字,被其标记的属性不会被序列化。比如在 AbstractList 里,之前提到的并发修改检查中用于记录结构性操作次数的变量 modCount,还有下面要介绍到的 ArrayList 的底层数组 elementData 就是被 transient 关键字修饰的。
更多的内容可以参考大佬的博文:Java transient关键字使用小记
二、成员变量
在 ArrayList 中,一共有四个常量,两个成员变量:
1 | private static final long serialVersionUID = 8683452581122892189L; |
我们来一个一个的解释他们的作用。
1.serialVersionUID
1 | private static final long serialVersionUID = 8683452581122892189L; |
用于序列化检测的 UUID,我们可以简单的理解他的作用:
当序列化以后,serialVersionUID 会被一起写入文件,当反序列化的时候,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
更多内容仍然可以参考大佬的博文:java类中serialversionuid 作用 是什么?举个例子说明
2.DEFAULT_CAPACITY
默认容量,如果实例化的时候没有在构造方法里指定初始容量大小,第一个扩容就会根据这个值扩容。
3.EMPTY_ELEMENTDATA
一个空数组,当调用构造方法的时候指定容量为0,或者其他什么操作会导致集合内数组长度变为0的时候,就会直接把空数组赋给集合实际用于存放数据的数组 elementData。
4.DEFAULTCAPACITY_EMPTY_ELEMENTDATA
也是一个空数组,不同于 EMPTY_ELEMENTDATA 是指定了容量为0的时候会被赋给elementData,而DEFAULTCAPACITY_EMPTY_ELEMENTDATA是在不指定容量的时候才会被赋给 elementData,而且添加第一个元素的时候就会被扩容。
DEFAULTCAPACITY_EMPTY_ELEMENTDATA和 EMPTY_ELEMENTDATA都不影响实际后续往里头添加元素,两者主要表示一个逻辑上的区别:前者表示集合目前为空,但是以后可能会添加元素,而后者表示这个集合一开始就没打算存任何东西,是个容量为0的空集合。
5.elementData
实际存放数据的数组,当扩容或者其他什么操作的时候,会先把数据拷贝到新数组,然后让这个变量指向新数组。
6.size
集合中的元素数量(注意不是数组长度)。
7.MAX_ARRAY_SIZE
允许的最大数组长度,之所以等于 Integer.MAX_VALUE - 8,是为了防止在一些虚拟机中数组头会被用于保持一些其他信息。
三、构造方法
ArrayList 中提供了三个构造方法:
ArrayList()ArrayList(int initialCapacity)ArrayList(Collection<? extends E> c)
1 | // 1.构造一个空集合 |
我们一般使用比较多的是第一种,有时候会用第三种,实际上,如果我们可以估计到实际会添加多少元素,就可以使用第二种构造器指定容量,避免扩容带来的消耗。
四、扩容缩容
ArrayList 的可扩展性是它最重要的特性之一,在开始了解其他方法前,我们需要先了解一下 ArrayList 是如何实现扩容和缩容的。
0.System.arraycopy()
在这之前,我们需要理解一下扩容缩容所依赖的核心方法 System.arraycopy()方法:
1 | /** |
我们举个例子,假如我们现在有 arr1 = {1,2,3,4,5}和 arr2 = {6,7,8,9,10},现在我们使用 arraycopy(arr1, 0, arr2, 0, 2),则意为:
使用从 arr1 索引为 0 的元素开始,复制 2 个元素,然后把这两个元素从 arr2 数组中索引为 0 的地方开始替换原本的元素,
1 | int[] arr1 = {1, 2, 3, 4, 5}; |
1.扩容
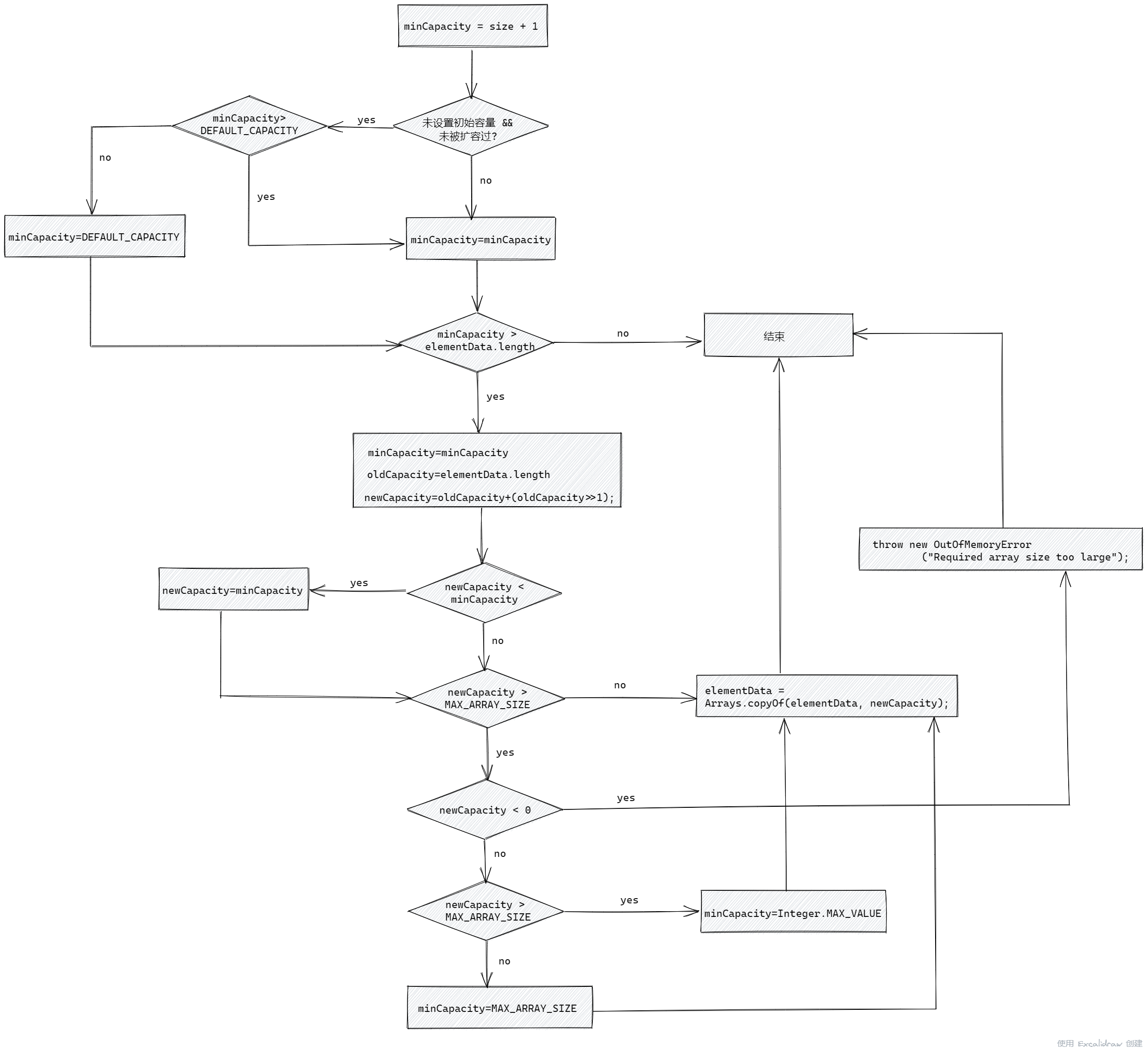
虽然在 AbstractCollection 抽象类中已经有了简单的扩容方法 finishToArray(),但是 ArrayList 没有继续使用它,而是自己重新实现了扩容的过程。ArrayList 的扩容过程一般发生在新增元素上。
我们以 add() 方法为例:
1 | public boolean add(E e) { |
(1)检查是否初次扩容
我们知道,在使用构造函数构建集合的时候,如果未指定初始容量,则内部数组 elementData 会被赋上默认空数组 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。
因此,当我们调用 add()时,会先调用 ensureCapacityInternal()方法判断elementData 是否还是DEFAULTCAPACITY_EMPTY_ELEMENTDATA,如果是,说明创建的时候没有指定初始容量,而且没有被扩容过,因此要保证集合被扩容到10或者更大的容量:
1 | private void ensureCapacityInternal(int minCapacity) { |
(2)检查是否需要扩容
当决定好了第一次扩容的大小,或者elementData被扩容过最少一次以后,就会进入到扩容的准备过程ensureExplicitCapacity(),在这个方法中,将会增加操作计数器modCount,并且保证新容量要比当前数组长度大:
1 | private void ensureExplicitCapacity(int minCapacity) { |
(3)扩容
最后进入真正的扩容方法 grow():
1 | // 扩容 |
这里可能有人会有疑问,为什么oldCapacity要等于elementData.length而不可以是 size()呢?
因为在 ArrayList,既有需要彻底移除元素并新建数组的真删除,也有只是对应下标元素设置为 null 的假删除,size()实际计算的是有元素个数,因此这里需要使用elementData.length来了解数组的真实长度。
回到扩容,由于 MAX_ARRAY_SIZE已经是理论上允许的最大扩容大小了,如果新容量比MAX_ARRAY_SIZE还大,那么就涉及到一个临界扩容大小的问题,hugeCapacity()方法被用于决定最终允许的容量大小:
1 | private static int hugeCapacity(int minCapacity) { |
ArrayList 的 hugeCapacity()与 AbstractCollection抽象类中的 hugeCapacity()是完全一样的,当 minCapacity > MAX_ARRAY_SIZE的情况成立的时候,说明现在的当前元素个数size容量已经等于 MAX_ARRAY_SIZE,数组已经极大了,这个时候再进行拷贝操作会非常消耗性能,因此最后一次扩容会直接扩到 Integer.MAX_VALUE,如果再大就只能溢出了。
以下是扩容的流程图:
2.缩容
除了扩容,ArrayList 还提供了缩容的方法 trimToSize(),但是这个方法不被任何其他内部方法调用,只能由程序猿自己去调用,主动让 ArrayList 瘦身,因此在日常使用中并不是很常见。
1 | public void trimToSize() { |
3.测试
我们可以借助反射,来看看 ArrayList 的扩容和缩容过程:
先写一个通过反射获取 elementData 的方法:
1 | // 通过反射获取值 |
然后实验看看:
1 | public static void main(String[] args) { |
五、添加 / 获取
1.add
1 | public boolean add(E e) { |
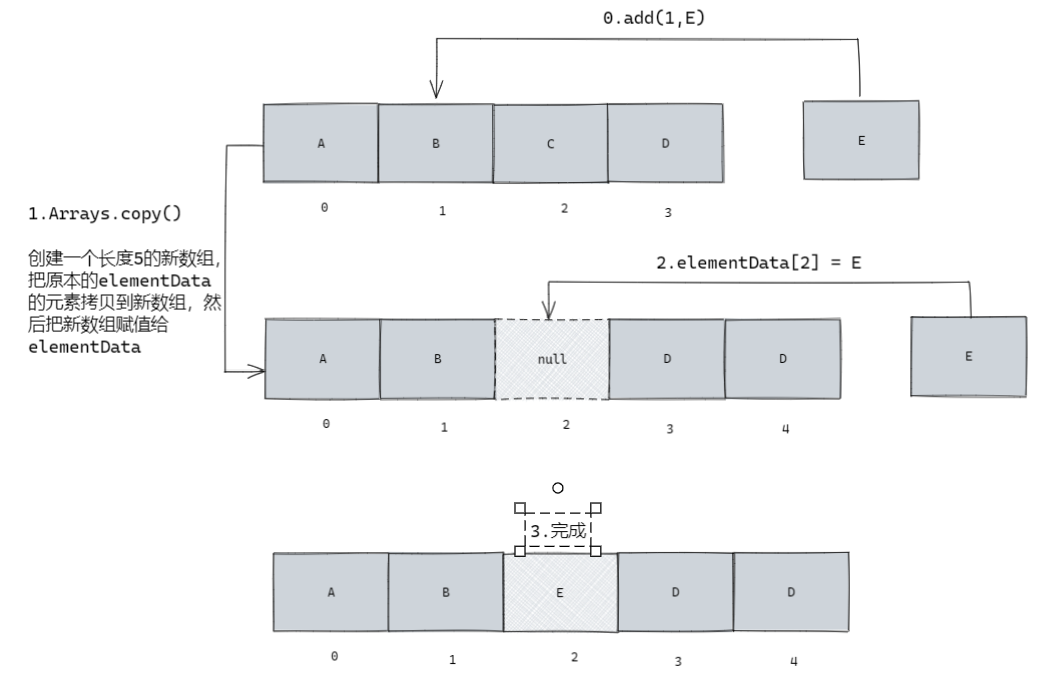
添加的原理比较简单,实际上就是如果不指定下标就插到数组尾部,否则就先创建一个新数组,然后把旧数组的数据移动到新数组,并且在这个过程中提前在新数组上留好要插入的元素的空位,最后再把元素插入数组。后面的增删操作基本都是这个原理。
2.addAll
1 | public boolean addAll(Collection<? extends E> c) { |
3.get
1 | public E get(int index) { |
六、删除 / 修改
1.remove
1 | public E remove(int index) { |
这里有用到一个fastRemove()方法:
1 | // fast 的地方在于:跳过边界检查,并且不返回删除的值 |
比较有趣的地方在于,remove()的时候检查的是index >= size,而 add()的时候检查的是 index > size || index < 0,可见添加的时候还要看看 index 是否小于0。
原因在于 add()在校验完以后,立刻就会调用System.arraycopy(),由于这是个 native 方法,所以出错不会抛异常;而 remve() 调用完后,会先使用 elementData(index)取值,这时如果 index<0 会直接抛异常。
2.clear
比较需要注意的是,相比起remove()方法,clear()只是把数组的每一位都设置为null,elementData的长度是没有改变的:
1 | public void clear() { |
3.removeAll / retainAll
1 | public boolean removeAll(Collection<?> c) { |
这两个方法都依赖于 batchRemove()方法:
1 | private boolean batchRemove(Collection<?> c, boolean complement) { |
上述这三个过程可能有点难一点理解,我们假设这是 retailAll(),因此 complement=true,执行流程是这样的:
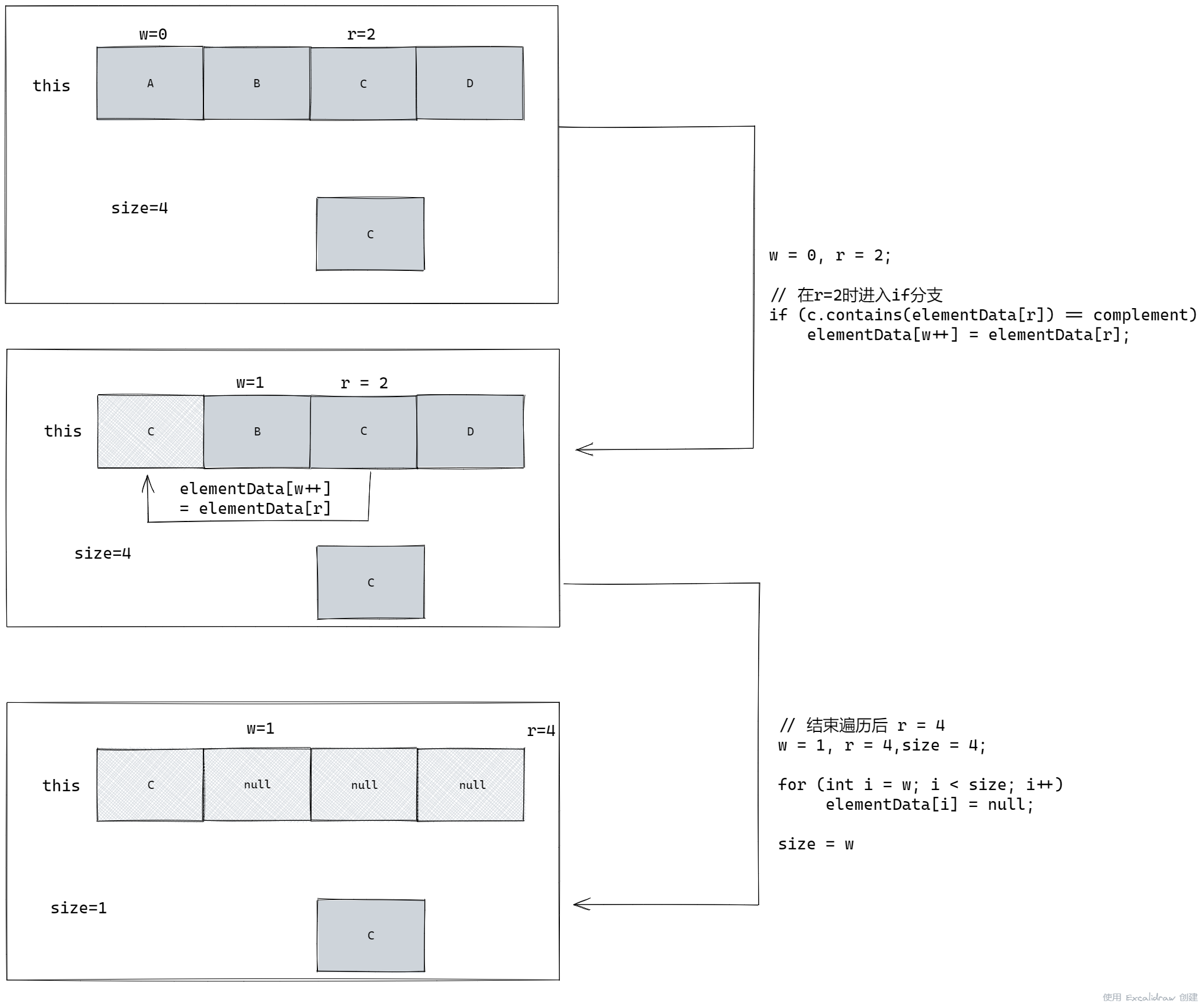
同理,如果是removeAll(),那么 w 就会始终为0,最后就会把 elementData 的所有位置都设置为 null。
也就是说,在遍历过程中如果不发生异常,就会跳过第二步,直接进入第三步。
当然,这是没有发生异常的情况,因此遍历完成后 r = size,那么如果遍历到 r = 2,也就是进入 if 分支后,程序发生了异常,尚未完成遍历就进入了 finallly 块,就会先进入第二步,也就是下面的流程:
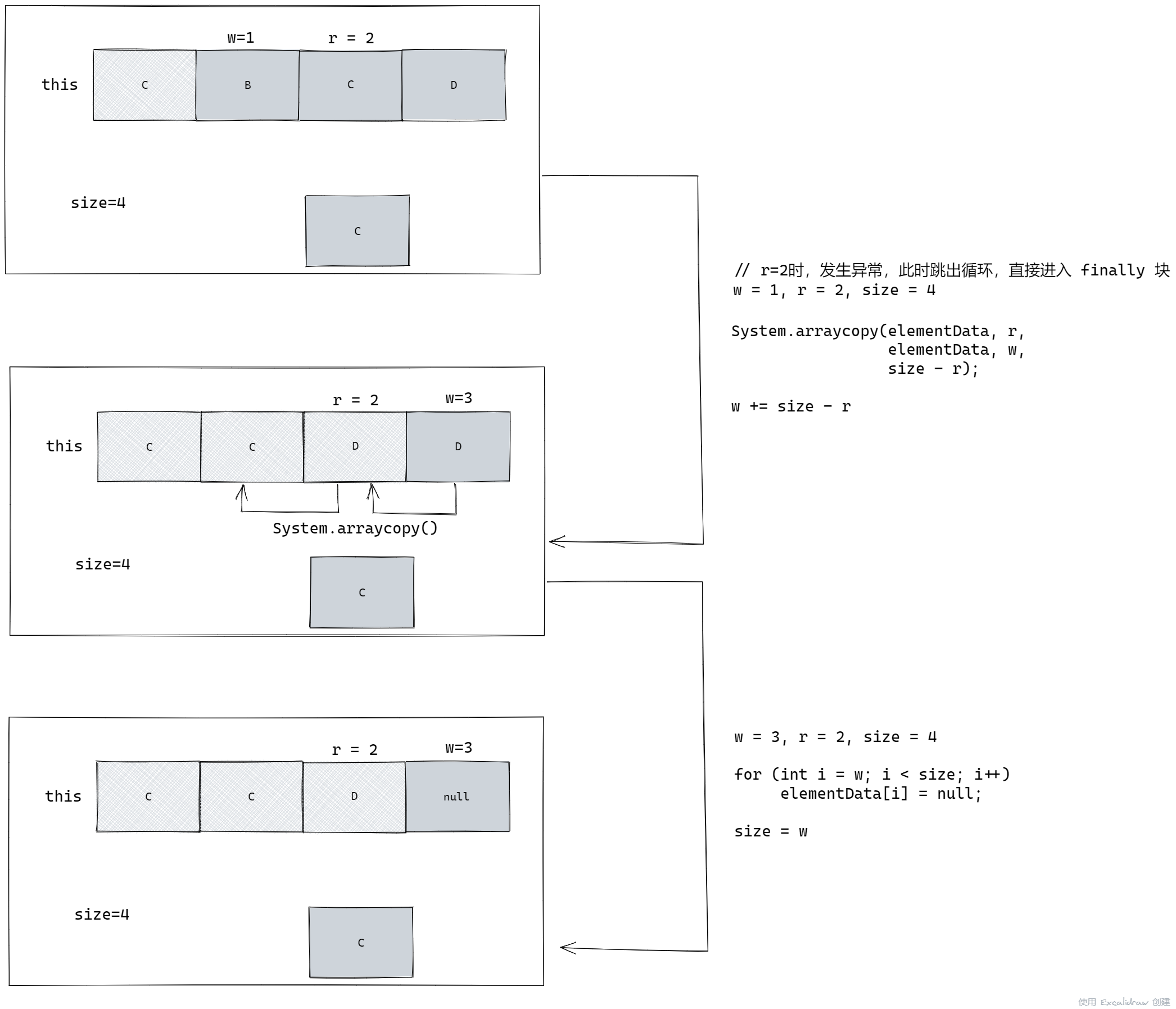
最终数组会变为 {C,C,D,null} ,只有最后一个 D 被删除。
4.removeIf
这个是 JDK8 以后的新增方法:
1 | public boolean removeIf(Predicate<? super E> filter) { |
5.set
1 | public E set(int index, E element) { |
6.replaceAll
这也是一个 JDK8 新增的方法:
1 | public void replaceAll(UnaryOperator<E> operator) { |
七、迭代
1.iterator / listIterator
ArrayList 重新实现了自己的迭代器,而不是继续使用 AbstractList 提供的迭代器。
和 AbstracList 一样,ArrayList 实现的迭代器内部类仍然是基础迭代器 Itr 和加强的迭代器 ListItr,他和 AbstractList 中的两个同名内部类基本一样,但是针对 ArrayList 的特性对方法做了一些调整:比如一些地方取消了对内部方法的调用,直接对 elementData 下标进行操作等。
这一块可以参考上篇文章,或者看看源码,这里就不赘述了。
2.forEach
这是一个针对 Collection 的父接口 Iterable 接口中 forEach 方法的重写。在 ArrayList 的实现是这样的:
1 | public void forEach(Consumer<? super E> action) { |
3.迭代删除存在的问题
到目前为止,我们知道有三种迭代方式:
- 使用
iterator()或listIterator()获取迭代器; forEach();- for 循环。
如果我们在循环中删除集合的节点,只有迭代器的方式可以正常删除,其他都会出问题。
或者更准确点说,只要会引起 modCount++的操作,不通过迭代器进行都会出现一些问题。
forEach
我们先试试使用 forEach():
1 | ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C","D")); |
可见会抛出 ConcurrentModificationException异常,我们回到 forEach()的代码中:
1 | public void forEach(Consumer<? super E> action) { |
由于在方法执行的开始就令 expectedModCount= modCount,遍历过程中每次都要检查 modCount == expectedModCount,这样如果我们在匿名函数中对元素做了一些结构性操作,导致 modCount增加,就会在下一次循环判断的时候跳出循环,由于此时modCount != expectedModCount,所以会直接进入 if 分支抛出 ConcurrentModificationException异常。
我们可以验证一下:
1 | ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C")); |
for循环
由于 for 循环过程不像 forEach()那样在循环的结构中进行并发修改检测,因此结构性操作不会出现ConcurrentModificationException,但是remove()会漏删一下元素。我们来验证一下:
1 | ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C","D")); |
可以看到,B 和 C 的删除被跳过了。实际上,这个问题和 AbstractList 的迭代器 Itr 中 remove() 方法遇到的问题有点像:
在 AbstractList 的 Itr 中,每次删除都会导致数组的“缩短”,在被删除元素的前一个元素会在 remove()后“补空”,落到被删除元素下标所对应的位置上,也就是说,假如有 a,b 两个元素,删除了下标为0的元素 a 以后,b 就会落到下标为0的位置。AbstractList 的 Itr 的解决方案是每次删除都把指向下一个的指针前移,那么 ArrayList 呢?
上文提到 ArrayList 的 remove() 调用了 fastRemove()方法,我们可以看看他是否就是罪魁祸首:
1 | private void fastRemove(int index) { |
可见数组“缩短”确实是导致的元素下标错位就是问题的根源,实际上,如果不是i < arrayList1.size()在每次循环都会重新获取长度,那么早就抛异常了。
换句话说,如果不调用 System.arraycopy()方法,数组就不会“缩短”,理论上就不会引起这个问题,所以我们不妨试试反向删除:
1 | ArrayList<String> arrayList1 = new ArrayList<>(Arrays.asList("A","B","C","D")); |
可见反向删除是没有问题的。
八、其他
1.indexOf / lastIndexOf / contains
相比起 AbstractList ,ArrayList 不再使用迭代器,而是改写成了根据下标进行for循环:
1 | // indexOf |
至于 contains() 方法,由于已经实现了 indexOf(),自然不必继续使用 AbstractCollection 提供的迭代查找了,而是改成了:
1 | public boolean contains(Object o) { |
2.subList
subList() 和 iterator()一样,也是返回一个特殊的内部类 SubList,在 AbstractList 中也已经有相同的实现,只不过在 ArrayList 里面进行了一些改进,大体逻辑和 AbstractList 中是相似的,这部分内容在前文已经有提到过,这里就不再多费笔墨。
3.sort
1 | public void sort(Comparator<? super E> c) { |
java 中集合排序要么元素类实现 Comparable 接口,要么自己写一个 Comparator 比较器。这个函数的参数指明了类型是比较器,因此只能传递自定义的比较器,在 JDK8 以后,Comparator 类提供的了一些默认实现,我们可以以类似 Comparator.reverseOrder() 的方式去调用,或者直接用 lambda 表达式传入一个匿名方法。
4.toArray
toArray() 方法在 AbstractList 的父类 AbstractCollection 中已经有过基本的实现,ArrayList 根据自己的情况重写了该方法:
1 | public Object[] toArray() { |
5.clone
ArrayList 实现了 Cloneable 接口,因此他理当有自己的 clone()方法:
1 | public Object clone() { |
要注意的是, Object.clone()是浅拷贝, Arrays.copyOf()也是浅拷贝,因此我们拷贝出来的 ArrayList 不同,内部的 elementData 不同,但是 elementData 中的数据,也就是容器中的数据还是相同的。我们举个例子:
1 | public static void main(String[] args){ |
6.isEmpty
1 | public boolean isEmpty() { |
九、总结
数据结构
ArrayList 底层是 Object[] 数组,被 RandomAccess 接口标记,具有根据下标高速随机访问的功能;
扩容缩容
ArrayList 扩容是扩大1.5倍,只有构造方法指定初始容量为0时,才会在第一次扩容出现小于10的容量,否则第一次扩容后的容量必然大于等于10;
ArrayList 有缩容方法trimToSize(),但是自身不会主动调用。当调用后,容量会缩回实际元素数量,最小会缩容至默认容量10;
ArrayList 的添加可能会因为扩容导致数组“膨胀”,同理,不是所有的删除都会引起数组“缩水”:当删除的元素是队尾元素,或者clear()方法都只会把下标对应的地方设置为null,而不会真正的删除数组这个位置;
迭代中的操作
ArrayList 在循环中删除——准确的讲,是任何会引起 modCount变化的结构性操作——可能会引起意外:
在
forEach()删除元素会抛ConcurrentModificationException异常,因为forEach()在循环开始前就获取了modCount,每次循环都会比较旧modCount和最新的modCount,如果循环进行了会使modCount变动的操作,就会在下一次循环开始前抛异常;在 for 循环里删除实际上是以步长为2对节点进行删除,因为删除时数组“缩水”导致原本要删除的下一下标对应的节点,却落到了当前被删除的节点对应的下标位置,导致被跳过。
如果从队尾反向删除,就不会引起数组“缩水”,因此是正常的。