概述
LinkedHashMap 是 Map 接口下一个线程不安全的,允许 null 的,基于哈希表的实现。它是 HashMap 的子类, 由于引入了双向链表的数据结构,除了拥有 HashMap 的所有特征外,他还可以以双向链表的方式操作和访问,并且提供按插入顺序或访问顺序两种顺序访问方式。
由于结构的特殊性,通过 LinkedHashMap,我们可以非常便捷的实现一个基于 LRU 算法的缓存容器。
这是关于 java 集合类源码的第七篇文章。往期文章:
一、LinkedHashMap 的数据结构
LinkedHashMap 是 HashMap 的子类,他的节点类 Entry 也继承了 HashMap 的节点类 Node 类。所以 LinkedHashMap 保留了 HashMap 的所有基本特征。
但是,不同的是,LinkedHashMap 在节点类 Entry 中增加了 after 和 before 两个指针用于指向前驱和后继节点,并且提供了头节点和尾节点的指针,也就是说,他实际上也可以认为是一条双向链表。
比如下图,依次按顺序插入三个节点:
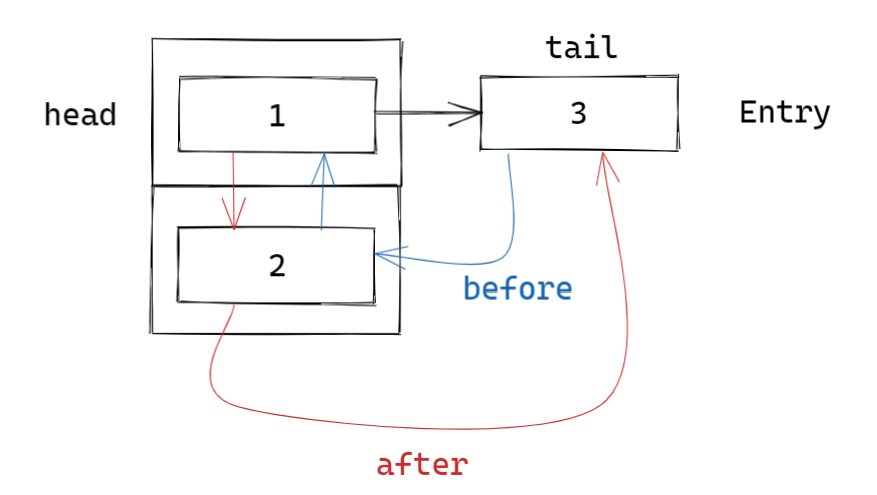
实际上,从链表的角度来看,也可以理解为这样:

二、成员变量
关于 HashMap 的成员变量,可以直接参考前文java集合源码分析(六):HashMap的第二节,故这里只了解 LinkedHashMap 的成员变量。
1 | // 链表头结点 |
三、构造方法
LinkedHashMap 的构造方法有五个,基本和 HashMap 的相同,但是多了 accessOrder 参数:
当不指定开启的时候,默认都为 false,此时我们遍历得顺序即是插入顺序。
若指定为 true,即按访问顺序访问的。默认排序仍然按插入顺序,但是当我们使用 get 方法访问的任意一个节点,则该节点就会被默认移动到队尾。
1 | // 使用指定容量和指定负载系数,默认按插入顺序 |
三、内部类
和 HashMap 相比,LinkedHashMap 只提供包括:
- 三种额外的集合视图类:LinkedKeySet,LinkedValues,LinkedEntrySet
- Entry 实现类:Entry(继承了 HashMap.Node)
- 迭代器抽象类:LinkedHashIterator
- 三种集合视图的迭代器类:LinkedKeyIterator,LinkedValueIterator,LinkedEntryIterator
共计八个实现类。
比较值得注意的是,由于要基于哈希值访问可以直接使用父类 HashMap 的相关迭代器或者集合视图,因此 LinkedHashMap 提供的迭代器和集合视图只用于基于链表的访问。
四、添加节点
1.父类中的putVal
LinkedHashMap 的插入直接使用了 HashMap 的方法,但是他基于 HashMap 留下的“后门”,巧妙的在 HashMap 的基础上实现了新功能。我们关注以下 HashMap 的 putVal()中的一些关键代码:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
可见 LinkedHashMap 与 HashMap 插入方法的区别就在于newNode(),afterNodeAccess()与 afterNodeInsertion()方法。
newNode()方法是用于创建节点,HashMap 已有实现,但是 LinkedHashMap 重写了此方法,使得创建节点的时候同时构建链表。
afterNodeAccess()与 afterNodeInsertion()两者在 HashMap 中都是空方法,在 LinkedHashMap 中提供了实现。
其中,afterNodeAccess()方法会让传入的节点移动到链表的尾端,而afterNodeInsertion()可能会根据情况删除最早添加节点。
2.newNode
newNode 方法分为两步,第一步创建一个 Entry 实例,第二步调用 linkNodeLast()方法将节点添加到链表尾部。
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { |
3.afterNodeAccess
afterNodeAccess 用于将节点移动到尾部,但是只有 accessOrder=true 并且尾节点不为 null 才会真正的移动节点。这个方法除了在 putVal 中被调用外,还在 get 或者 replace 等方法被调用。也就是说,我们访问一个节点以后,如果允许按访问顺序访问,那么被访问的节点就会被移动到链表尾部。
1 | void afterNodeAccess(Node<K,V> e) { // move node to last |
4.afterNodeInsertion
afterNodeInsertion()方法与其名字一样,只在添加和修改后会被调用。
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
这里的判断条件 evict是 HashMap 创建时会传入的一个参数,表示的是“集合是否处于创建模式”,只有使用 Map 集合作为构造器参数的时候会为 true,其他时候都为 false。
而 removeEldestEntry()方法如下:
1 | protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { |
这个方法总是返回一个 false 值。
根据以上的判断条件,我们可以看出,这个方法一般情况下基本不可能会进入 if 分支,但是根据 removeEldestEntry()的注释提供的示例,如果我们创建一个集合类,并且继承了 LinkedHashMap ,那么我们可以补充并且重写如下的代码:
1 | private static final int MAX_ENTRIES = 100; |
此时,假如容器容量固定为100,则当添加101个元素的时候,就会移除最古老的元素,也就是头结点的元素,这恰好是 LRU 算法的思想。基于这一点,我们可以自定义容器,通过继承 LinkedHashMap 来实现基于 LRU 算法的缓存。
五、获取元素
LinkedHashMap 的 get 是自己重新实现的方法。
1 | public V get(Object key) { |
和父类的 put 方法一样,如果允许按访问顺序排序,则在访问元素过后,该元素会排至链表尾部。
六、删除元素
LinkedHashMap 的 remove 和 put 一样,都是通过在父方法中调用空实现方法,然后子类重写空实现方法,从而在父类的方法基础上扩展。
LinkedHashMap 的 remove 仍然直接使用 HashMap 的 remove() 方法,但是在 remove 的底层方法 removeNode()中,会在删除节点以后调用 afterNodeRemoval(),在 HashMap 中这是一个空方法,而 LinkedHashMap 实现了他。
因为 HashMap 的删除只是从数据结构上删除节点,所以 LinkedHashMap 需要自己去通过afterNodeRemoval()方法删除节点之间的引用关系。
1 | void afterNodeRemoval(Node<K,V> e) { // unlink |
七、迭代与顺序性
1.迭代方法
LinkedHashMap 与 HashMap 一样,都可用通过集合视图迭代,同时也可以通过自己重写的 forEach()方法进行迭代。
由于 HashMap 实现了 fast-fail 机制,所以 LinkedList 同样也会针对迭代过程中的并发修改抛出 ConcurrentModificationException异常。
2.为什么迭代是顺序性的
结构基础
首先,根据上文,我们知道 LinkedList 在 HashMap 的哈希表的基础上又实现了双向链表的数据结构,并且在 get 和 put 中,通过实现父类的空方法的方式,扩展了 HashMap 的添加和修改。当我们要进行以上操作的时候:
- 调用重写过的
newNode()方法创建节点,在创建节点的同时将新节点添加到链表尾部; - 获取节点后,调用
afterNodeAccess,如果允许按访问顺序访问,就会把要修改/获取的节点移动到链表尾部; - 调用
afterNodeInsertion(),在插入结束后移除最老节点。只有在 LinkedHashMap 的基础上重写removeEldestEntry()才能真的实现该功能。
第一点保证了链表最开始总是按照插入顺序排序,第二点则提供了按访问顺序排序的排序方式。
迭代方式
根据前文,我们知道三个集合视图本质都在使用集合不对外暴露的迭代器,而在 LinkedHashList 中这个迭代器就是 LinkedHashIterator。这个迭代器是的迭代方式就是把链表从头迭代到尾,这是就是顺序的。
而三个集合视图是分别在迭代得到的元素的基础上,分别拿 Entry,value 或者 key。LinkedHashList 又重写了 entry(),values(),key()方法,因此通过这些方法获得的集合视图也是有序的。
八、基于 LinkedHashMap 实现的缓存容器
LRU(Least Recently Used)即最近最少使用,这个算法被广泛的用于缓存等领域。简单的用链表描述一下,就是规定一个容量一定的链表,当节点被访问时就移到队尾,当节点数量大于阈值的时候,就移除头结点以腾出空间。
换句话说,只需要一个集合能满足三点即可:
- 容量一定
- 被访问的节点移到尾部
- 超过容量就删除头部节点
若我们基于 LinkedHashMap ,则只需要重写 removeEldestEntry()方法,并且在构造方法中指定按访问顺序排序即可:
1 | public class LruLink<K, V> extends LinkedHashMap<K, V> { |
然后测试一下:
1 | Map<String, String> link = new LruLink<>(3); |
九、总结
数据结构
LinkedHashMap 是 HashMap 的子类,它在 HashMap 提供的哈希表的基础上又实现了双向链表,链表默认按插入顺序排序,这是他有序性的结构基础。
有序性
LinkedHashMap 默认按插入顺序排序,可以通过在构造方法中指定 accessOrder=true,可以开启按访问顺序排序,此时,当访问节点后,被访问的节点会被移动到链表的尾部。
迭代
LinkedHashMap 也重写了 forEach(),因此它与 HashMap一样,可以通过 forEach()或者视图集合进行迭代。此外,它同样实现了 fast-fail 机制。
LinkedHashMap 重写了 entrySet(),values()和 keySet() 方法,并且视图集合的迭代器都依赖于 LinkedHashIterator,而该迭代器总是从链表头迭代到链表位,因此通过视图进行迭代也是有序的。
LRU 容器的实现
自定义一个类继承 LinkedHashMap,重写 removeEldestEntry(),并在父类构造方法中指定 accessOrder=true开启按访问顺序排序即可。另外,需要在父类构造器中指定容量需要大于指定容量 / 负载系数,避免扩容。