概述
在 java 中,线程池 ThreadPoolExecutor 是一个绕不过去的类,它是享元模式思想的体现,通过在容器中创建一定数量的线程加以重复利用,从而避免频繁创建线程带来的额外开销。一个设置合理的线程池可以提高任务响应的速度,并且避免线程数超过硬件能力带来的意外情况。
在本文,将深入线程池源码,了解线程池的底层实现与运行机制。
一、构造方法
ThreadPoolExecutor 类一共提供了四个构造方法,我们基于参数最完整构造方法了解一下线程池创建所需要的变量:
1 | public ThreadPoolExecutor(int corePoolSize, // 核心线程数 |
- 核心线程数:即长期存在的线程数,当线程池中运行线程未达到核心线程数时会优先创建新线程;
- 最大线程数:当核心线程已满,工作队列已满,同时线程池中线程总数未超过最大线程数,会创建非核心线程;
- 非核心线程闲置存活时间:当非核心线程闲置的时的最大存活时间;
- 时间单位:非核心线程闲置存活时间的时间单位;
- 任务队列:当核心线程满后,任务会优先加入工作队列,等等待核心线程消费;
- 线程工厂:线程池创建新线程时使用的线程工厂;
- 拒绝策略:当工作队列与线程池都满时,用于执行的策略;
二、线程池状态
1.线程池状态
线程池拥有一个 AtomicInteger 类型的成员变量 ctl ,通过位运算分别使用 ctl 的高位低位以便在一个值中存储线程数量以及线程池状态。
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
2.线程状态的计算
这里比较不好理解的是上述-1的位运算,下面我们来分析一下:
在计算机中,二进制负数一般用补码表示,即源码取反再加一。但又有这种说法,即将最高位作为符号位,0为正数,1为负数。实际上两者是可以结合在一起看的。假如数字是单字节数,1 字节对应8 bit,即八位,现在,我们要计算 - 1。
按照第二种说法,最高位为符号位,则有 1/000 0001,然后按第一种说法取反后+1,并且符号位不变,则有 1/111 1110 + 1,即 1/111 1111。
现在回到 -1 << COUNT_BITS这行代码:
一个 int 是 4 个字节,对应 32 bit,按上述过程 -1 转为二进制即为 1/111......1111(32个1), COUNT_BITS是 29,-1 左移 29 位,最终得到 111.0...0000。
同理,计算其他的几种状态,可知分别是:
| 状态 | 二进制 |
|---|---|
| RUNNING | 111...0....00 |
| SHUTDOWN | 000...0....00 |
| STOP | 001...0....00 |
| TIDYING | 010...0....00 |
| TERMINATED | 011...0....00 |
其中,我们可以知道 SHUTDOWN 状态转为十进制也是 0 ,而 RUNNING 作为有符号数,它的最高位是 1,说明转为十进制以后是个负数,其他的状态最高位都是 0,转为十进制之后都是正数,也就是说,我们可以这么认为:
小于 SHUTDOWN 的就是 RUNNING,大于 SHUTDOWN 就是停止或者停止中。
这也是后面状态计算的一些写法的基础。比如 isRunning()方法:
1 | private static boolean isRunning(int c) { |
3.线程状态与工作线程数的获取
1 | // 根据当前运行状态和工作线程数获取当前的 ctl |
前面获取状态的时候调用了 ctlOf()方法,根据前面,我们可以知道,CAPACITY实际上是 29 位,而线程状态用的是 32 - 30 共 3 位,也就是说,ctl 共 32 位,高3 位用于表示线程池状态,而低 29 位表示工作线程的数量。
这样上述三个方法就很好理解了:
ctlOf():获取 ctl。将工作线程数量与运行状态进行于运算,假如我们处于 RUNNING,并且有 1 个工作线程,那么 ctl = 111....000 | 000.... 001,最终得到 111 ..... 001;
runStateOf():获取运行状态。继续根据上文的数据,
~CAPACITY取反即为 111....000,与运行状态 111...0000 与运算,最终得到 111....000,相当于低位掩码,消去低 29 位;workerCountOf():获取工作线程数。同理,
c & CAPACITY里的 CAPACITY 相当于高位掩码,用于消去高 3 位,最终得到 00...001,即工作线程数。
同理,如果要增加工作线程数,就直接通过 CAS 去递增 ctl,比如新建线程中使用的公共方法:
1 | private boolean compareAndIncrementWorkerCount(int expect) { |
要改变线程池状态,就根据当前工作线程和要改变的状态去合成新的 ctl,然后 CAS 改变 ctl,比如 shutdown()中涉及的相关代码:
1 | private void advanceRunState(int targetState) { |
三、任务的创建与执行
线程池任务提交方法是 execute(),根据代码可知,当一个任务进来时,分四种情况:
- 当前工作线程数小于核心线程数,启动新线程;
- 当前工作线程数大于核心线程数,但是未大于最大线程数,尝试添加到工作队列;
- 当前线程池核心线程和队列都满了,尝试创建新非核心线程。
- 非核心线程创建失败,说明线程池彻底满了,执行拒绝策略。
1 | public void execute(Runnable command) { |
1.添加任务
添加任务依靠 addWorker()方法,这个方法很长,但是主要就干了两件事:
- CAS 让 ctl 的工作线程数 +1;
- 启动新的线程;
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
2. 任务对象Worker
根据上文,不难发现,在线程池中线程往往以 Worker 对象的方式存在,那么这个 Worker 又是何方神圣?
1 | private final class Worker |
这个 Worker 类继承了 AQS,也就是说,他本身就相当于一个同步队列,结合他的成员变量 thread 和 firstTask,可以知道他实际上就是我们线程池中所说的“线程”。除了父类 AQS 本身提供的独占锁以外,Worker 还提供了一些检查任务线程运行状态以及中断线程相关的方法。
此外,线程池中还有一个工作队列 workers,用于保存当前全部的 Worker:
1 | private final HashSet<Worker> workers = new HashSet<Worker>(); |
3.任务的启动
当调用 Worker.run()的时候,其实调用的是 runWorker()方法。
runWorker()方法实际上就是调用线程执行任务的方法,他的逻辑大题是这样的:
- 拿到入参的新 Worker,一直循环获取 Worker 里的任务;
- 加锁然后执行任务;
- 如果执行完任务流程,并且没有发生异常导致 Worker 挂掉,就直接复用 Worker(在获取任务的方法
getTask()中循环等待任务); - 如果执行完任务流程后发现发生异常导致 Worker 挂掉,就从工作队列中移除当前 Worker,并且补充一个新的;
如果整个流程执行完毕,就删除当前的 Worker。
1 | final void runWorker(Worker w) { |
4.任务的获取与超时处理
在 runWorker()方法中,通过 getTask()方法去获取任务。值得注意的是,超时处理也在此处,简单的来说,整套流程是这样的:
- 判断线程池是否关闭,工作队列是否为空,如果是说明没任务了,直接返回null,否则接着往下判断;
- 判断当前是否存在非核心线程,如果是说明需要进行超时处理;
- 获取任务,如果不需要超时处理,则直接从任务队列获取任务,否则根据 keepaliveTime 阻塞一段时间后获取任务,如果获取不到,说明非核心线程超时,返回 null 交给
runWorker()中的processWorkerExit()方法去删除;
换句话说,runWorker()方法一旦执行完毕,必然会删除当前的 Worker,而通过 getTask()拿任务的 Worker,在线程池正常运行的状态下,核心线程只会一直在 for 循环中等待直到拿到任务,而非核心线程超时以后拿不到任务就会返回一个 null,然后回到 runWorker()中走完processWorkerExit()方法被删除。
1 | private Runnable getTask() { |
四、线程池的中断
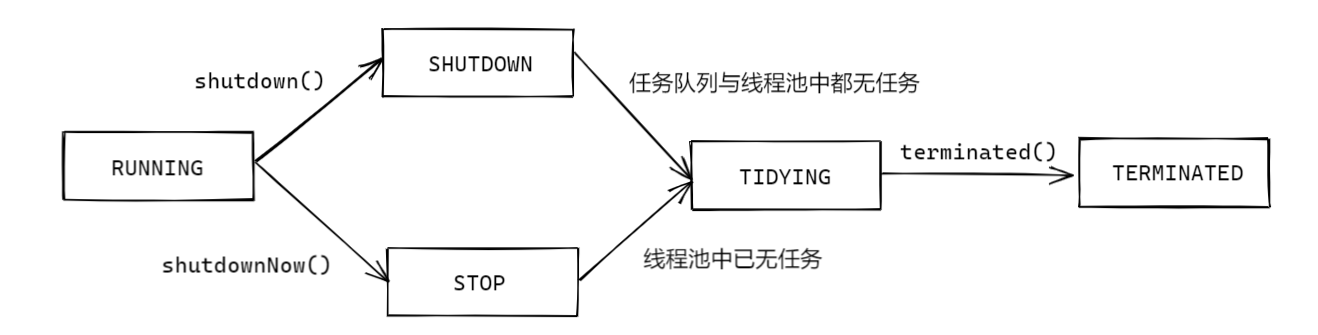
线程池的中断方法分为三种:
shutdown():中断线程池,不再添加新任务,同时等待当前进行和队列中的任务完成;shutdownNow():立即中断线程池,不再添加新任务,同时中断所有工作中的任务,不再处理任务队列中任务。
1.shutdown
shutdown 是有序关闭。主要干了三件事:
- 改变当前线程池状态为 SHUTDOWN;
- 将当前工作队列中的全部线程标记为中断;
- 完成上述过程后将线程池状态改为 TIDYING
1 | public void shutdown() { |
其中,interruptIdleWorkers()方法如下:
1 | private void interruptIdleWorkers(boolean onlyOne) { |
2.shutdownNow
shutdownNow() 与 shutdown()流程类似,但是会直接将状态转为 STOP,在 addWorker() 或者getTask()等处理任务的相关方法里,会针对 STOP 或更进一步的状态做区分,将不会再处理任务队列中的任务,配合drainQueue()方法以删除任务队列中的任务。
1 | public List<Runnable> shutdownNow() { |
五、拒绝策略
当任务队列已满,并且线程池中线程也到达最大线程数的时候,就会调用拒绝策略。也就是reject()方法
1 | final void reject(Runnable command) { |
拒绝策略共分四种:
- AbortPolicy:拒绝策略,直接抛出异常,默认策略;
- CallerRunsPolicy:调用者运行策略,用调用者所在的线程来执行任务;
- DiscardOldestPolicy:弃老策略,无声无息的丢弃阻塞队列中靠最前的任务,并执行当前任务;
- DiscardPolicy:丢弃策略,直接无声无息的丢弃任务;
我们可以简单的了解一下他们的实现:
AbortPolicy
1 | throw new RejectedExecutionException("Task " + r.toString() + |
CallerRunsPolicy
1 | public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { |
DiscardOldestPolicy
1 | public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { |
DiscardPolicy
1 | public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { |
六、线程池的钩子函数
和 HashMap 与 LinkedHashMap 中的行为有点类似,在线程池的代码中,有些方法调用了一些具有空实现的方法,这些方法是提供给用户去继承并重写的钩子函数,主要包括三个:
beforeExecute():在执行任务之前回调afterExecute():在任务执行完后回调terminated():在线程池中的所有任务执行完毕后回调
通过继承 ThreadPoolExecutor 类,并重写以上三个方法,我们可以进行监控或者输出日志,更方便的了解线程池的状态。
值得一提的是,afterExecute()方法的入参类型是(Runnable r, Throwable t),也就是说,如果线程运行中抛出异常,我们也可以通过该方法去捕获异常并作出相应的处理。
七、总结
线程池提供了四个构造方法,参数最全的构造方法参数按顺序有:核心线程数,最大线程数,非核心线程闲置存活时间,存活时间单位,任务队列,线程工厂,拒绝策略。
线程池共有五种状态,分别是:RUNNING,SHUTDOWN,STOP,TYDYING,TERMINATED,它们与工作线程数量一同记录在成员变量 ctl 中,其中高 3 位用于记录状态,低 29 位用于记录工作线程数,实际使用中通过位运算去获取。
线程池中任务线程以继承了 AQS 的 Worker 类的实例形式存在。当添加任务时,会有四种情况:核心线程不满,优先创建核心线程;核心线程满,优先添加任务队列;核心线程与队列都满,创建非核心线程;线程和队列都满,则执行拒绝策略。
其中,拒绝策略分为四类,默认的拒绝策略 AbortPolicy;调用者运行策略 CallerRunsPolicy;弃老策略 DiscardOldestPolicy;丢弃策略 DiscardPolicy。
线程池的中断有两个方法:shutdown()与 shutdownNow(),两者都会让线程池不再接受新任务,但是 shutdown()会等待当前与任务队列中的任务执行完毕,而 shutdownNow()会直接中断当前任务,忽略并删除任务队列中的任务。
线程池提供了beforeExecute(),afterExecute(),terminated()三个钩子函数,其中,afterExecute()的入参含有抛出的异常,因此可以借由该方法处理线程池中线程抛出的异常。