前言
众所周知,spring 从 2.5 版本以后开始支持使用注解代替繁琐的 xml 配置,到了 springboot 更是全面拥抱了注解式配置。平时在使用的时候,点开一些常见的等注解,会发现往往在一个注解上总会出现一些其他的注解,比如 @Service:
1 |
|
大部分情况下,我们可以将 @Service 注解等同于 @Component 注解使用,则是因为 spring 基于其 JDK 对元注解的机制进行了扩展。
在 java 中,元注解是指可以注解在其他注解上的注解,spring 中通过对这个机制进行了扩展,实现了一些原生 JDK 不支持的功能,比如允许在注解中让两个属性互为别名,或者将一个带有元注解的子注解直接作为元注解看待,或者在这个基础上,通过 @AliasFor 或者同名策略让子注解的值覆盖元注解的值。
本文将基于 spring 源码 5.2.x 分支,解析 spring 如何实现这套功能的。
这是系列的第二篇文章,将详细介绍 Spring 是如何解析 @AliasFor,实现各种别名功能。
相关文章:
一、创建合并注解聚合
1、入口
在 AnnotatedElementUtils 这个工具类中,所有带有 Merged 关键字的方法皆用于提供合并注解支持。
所谓合并注解,其实就是以前文提到 MergedAnnotation 为基础实现的一系列功能,包括:
- 对基于
@AliasFor注解属性别名机制的支持; - 对注解及元注解的合成支持;
我们可以点开 AnnotatedElementUtils 工具类中的常用方法 findMergedAnnotation:
1 | public static <A extends Annotation> A findMergedAnnotation(AnnotatedElement element, Class<A> annotationType) { |
大体过程分三步:
- 通过
findAnnotations获得合并注解聚合MergedAnnotations,该对象表示与指定AnnotatedElement关联的全部注解的聚合体; - 从
MergedAnnotations通过get方法获取符合条件的合并注解MergedAnnotation,该过程将从AnnotatedElement关联的全部注解中选出所需的注解类型,然后解析其各种映射关系,并变为一个合并注解; - 然后将该合并注解通过
synthesize方法合成为一个符合条件的普通注解,该过程将基于处理后的合并注解,使用 JDK 动态代理生成一个指定注解类型的代理对象;
这里我们重点关注 findMergedAnnotation 方法,以及调用 MergedAnnotations.get 方法后,合并注解聚合是如何在获得层级结构中的注解后,对其元注解和相关属性的解析的。
2、TypeMappedAnnotations
AnnotatedElementUtils.findAnnotations 获取了一个 MergedAnnotations 对象,该方法经过一系列的跳转,最终会得到一个 TypeMappedAnnotations 实现类实例:
1 | static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy, |
在前文我们知道,TypeMappedAnnotations 是 MergedAnnotations 接口的默认实现,他表示由 AnnotationScanner 从同一个 AnnotatedElement 上扫描出来的注解们转为的一批合并注解 MergedAnnotation。
举个例子,假如现有 AnnotatedElement 对象 Foo.class,他上面有一些注解,则理论上转为 MergedAnnotations 的过程如下:

不过当 TypeMappedAnnotations 创建以后,内部的 MergedAnnotation 并没有真正的被创建,而是需要等到调用 TypeMappedAnnotations 才会完成注解的搜索、解析与合并过程,因此在这个阶段,一个 TypeMappedAnnotations 只能表示一组来直接或间接自于同一个 AnnotatedElement 的注解之间的映射关系。
二、元注解的解析
TypeMappedAnnotations 创建后需要等到调用时才会初始化,当调用 MergedAnnotations.get 方法时,会创建一个 MergedAnnotationFinder 用于获取符合条件的 MergedAnnotation:
1 | public <A extends Annotation> MergedAnnotation<A> get(Class<A> annotationType, |
关于 AnnotationScanner 是如何使用 MergedAnnotationFinder 的过程在上文已经详细介绍了,这里就不再赘述,我们直接跳到 MergedAnnotationFinder.process 方法:
1 |
|
这里我们需要重点关注 AnnotationTypeMappings 和 AnnotationTypeMapping 的创建,这两者才是真正用于解析与维护原始注解对象信息的主题。
1、创建元注解聚合体
首先先给出定义,AnnotationTypeMappings 用于表示某一个注解类上全部元注解,对应的还有一个 AnnotationTypeMapping ,它表示一个具体的元注解对象。
AnnotationTypeMappings 与 MergedAnnotations 的设计思路一样,它表示一组 AnnotationTypeMapping 对象的聚合状态,同时用于提供对 AnnotationTypeMapping 的创建和搜索等功能。
某种程度上来说,AnnotationTypeMappings 其实就是一个注解类的元注解结合体。
我们看 AnnotationTypeMappings.forAnnotationType 静态方法,该方法用于根据一个注解类型创建 AnnotationTypeMappings 对象实例:
1 | static AnnotationTypeMappings forAnnotationType(Class<? extends Annotation> annotationType, |
而一切的秘密都在 AnnotationTypeMappings 的构造方法中:
1 | private AnnotationTypeMappings(RepeatableContainers repeatableContainers, |
这里重点分为两步:
- 调用
AnnotationTypeMappings.addAllMappings方法,解析入参注解类型的全部元注解,将其转为AnnotationTypeMapping对象; - 调用全部已解析好的
AnnotationTypeMapping对象的afterAllMappingsSet方法,做一些基本的校验;
2、收集元注解
在 AnnotationTypeMappings 创建时需要重点关注 AnnotationTypeMappings.addAllMappings 方法,该方法实际上就是元注解解析的主体,用于根据广度优先,把一个注解类上的全部元注解都转为 AnnotationTypeMapping 并加入 AnnotationTypeMappings 中:
1 | private void addAllMappings(Class<? extends Annotation> annotationType) { |
解析后的 AnnotationTypeMappings 大概可以参考下图:
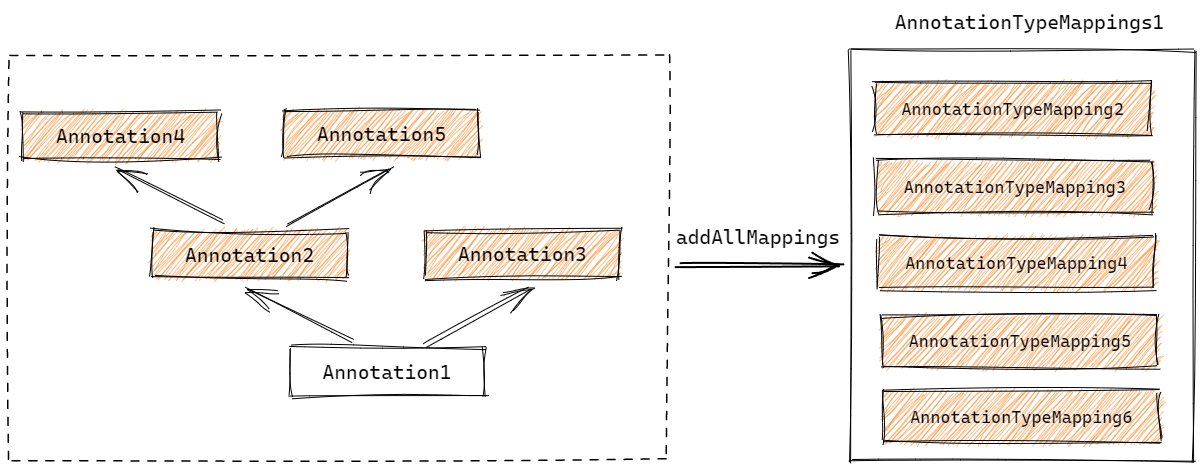
不过这个图仍然不够准确,因为 AnnotationTypeMapping 之间还会维持一个彼此间的引用关系,从而保证 AnnotationTypeMapping 彼此之间也能够区分父子关系。
3、解析元注解
AnnotationTypeMapping 直译叫做注解类型映射,之所以叫映射,是因为一个类型映射对象总是跟一个元注解一一对应,它持有原始注解的引用,此外还会记录注解属性以及其源注解的一些信息。
实际上,@AliasFor 以及其他注解属性的映射也在这里完成,不过本节先重点关注其本身的属性:
1 | AnnotationTypeMapping( AnnotationTypeMapping source, |
因此,通过构造函数不难看出,AnnotationTypeMapping 之间其实会形成一个类似单向链表的结构,我们根据此调整上一节末尾给出的图例:
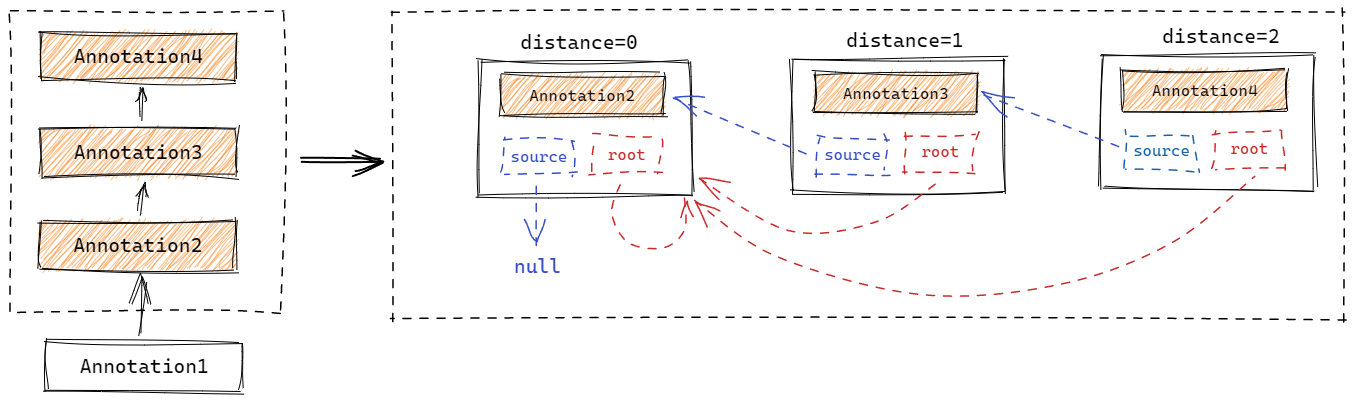
至此,通过 AnnotationTypeMappings 可以直接管理所有的 AnnotationTypeMapping,而通过独立的 AnnotationTypeMapping,又可以追溯元注解之间的父子关系。
三、属性解析
通过上文,我们分析完元注解的解析问题,通过 AnnotationTypeMappings 或 AnnotationTypeMapping 都可以完成的元注解树结构的访问,不过仍然还没说清楚Spring 支持的 @AliasFor 以及基于元注解的各种属性映射机制是怎么实现的。
这些涉及注解属性的映射,都是在 AnnotationTypeMapping 创建时,在构造方法里通过解析注解属性,以及判断元注解之间关联关系完成的。
继续看 AnnotationTypeMapping 的构造函数中属性解析解析部分:
1 | AnnotationTypeMapping( AnnotationTypeMapping source, |
关于属性解析部分,大概分为五部分内容:
- 解析注解属性;解析注解的属性,将其转为
AttributeMethods对象; - 解析
@AliasFor注解:基于AttributeMethods对象,解析注解带有@AliasFor注解的属性; - 映射互为别名的属性:为该注解内通过
@AliasFor形成互为别名关系的属性设置对应的MirrorSet; - 映射子注解对元注解属性的别名关系:将子注解中通过
@AliasFor指向父注解的属性的属性值,覆盖到父注解的对应属性上; - 令子注解覆盖父注解的同名属性:将子注解中与父注解同名的属性的属性值,覆盖到父注解的对应属性上;
1、解析无别名注解属性
属性解析的第一步,在 AnnotationTypeMapping 中,注解的属性会被解析为 AttributeMethods 对象:
1 | static AttributeMethods forAnnotationType( Class<? extends Annotation> annotationType) { |
这个类本质上就是通过 Class.getDeclaredMethods 获取到的注解属性的 Method 数组,在 AnnotationTypeMapping 中,所有的属性都通过它在 AttributeMethods 中的数组下标访问和调用。
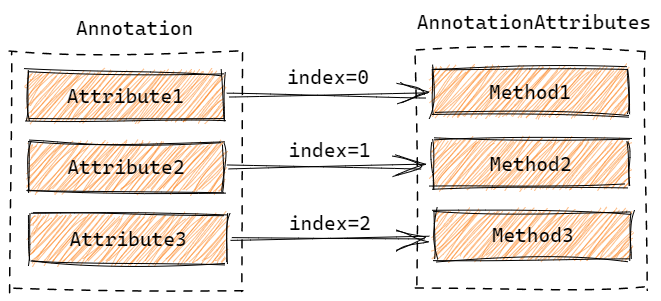
在构造函数中,我们也能看到提前声明了好几个数组:
1 | this.aliasMappings = filledIntArray(this.attributes.size()); |
这些数组都与属性映射有关,任何一个属性的相关映射信息,都可以通过其在 AttributeMethods 中对应的数组下标,从这些关联的数组对应位置获得。
2、解析带@AliasFor的别名属性
属性解析的第二步,在 AnnotationTypeMapping.resolveAliasedForTargets 方法中,AnnotationTypeMapping 会将所有带有 @AliasFor 注解,或者被子注解直接/间接通过 @AliasFor 指向的属性都解析到一个名为 aliasedBy 的类型为 Map<Method, List<Method>> 的成员变量中:
1 | private Map<Method, List<Method>> resolveAliasedForTargets() { |
resolveAliasTarget 最终将获得@AliasFor注解所指定的别名方法,具体如下:
1 | private Method resolveAliasTarget(Method attribute, AliasFor aliasFor, boolean checkAliasPair) { |
在这一步,他做了以下逻辑处理:
- 确定别名属性所在的注解类:若
@AliasFor.annotation属性保持默认值Annotation.class,则认为别名属性所在的注解就是当前解析的注解; - 确定别名属性对应的方法名:优先获取
@aliasFrom.attribute同名属性,若@AliasFrom.attribute为空则获取@AliasFrom.value指定的属性名; - 从指定的注解类获取方法名对应的属性;
- 校验该别名方法对应方法是否不是当前注解属性的方法;
- 校验别名方法返回值类型与当前注解属性的方法返回值类型是否一致;
- 校验声明该方法的类就是注解指定的注解类;
最终,完成这一步后,将构建出以别名方法作为 key,当前注解中对应的原始属性的方法作为 value的别名属性-原始属性映射表 aliasedBy。
这里有个比较有意思的地方,@AliasFor 注解中, value 和 attribute 属性同样存在 @AliasFor 注解,但是实际上这个注解是不生效的,因为在 Spring 在这边的实现实际上并没有让 @AliasFor 支持类似自举的机制。
另外,更有意思是,根据这些条件,你可以看出来,@AliasFor 不是一定要成对使用的,实际只要有一个 @AliasFor 出现,镜像关系就可以构建,如果你愿意,在不违背上述条件的情况下甚至可以同时有多个关联的别名字段:
1 |
|
对任意一个字段赋值等同于给所有字段赋值。
四、映射属性别名
Spring 中,支持令同一注解中的两个属性——不过在上文证明其实也支持多个——形成别名,即只要任意两个属性中的至少一个使用 @AliasFor 指向对方,则对其中一个属性的赋值,另一个属性也会得到。
而这些别名属性的映射关系,都会在 processAliases 完成解析:
1 | private void processAliases() { |
在这里,AnnotationTypeMapping 会遍历 AnnotationAttributes ,然后一次处理每一个注解属性,而这里分为对别名属性的收集和处理过程:
- 收集关联属性:从当前元注解的根注解,也就是
root开始,一层一层的向上找,将所有直接或间接与当前注解属性相关的,当前以及其他注解的属性; - 处理关联属性:根据搜集到的属性上的
@AliasFor注解,如果它们在同一注解中形成了别名关系,则为它们创建MirrorSet集合,构建彼此间的映射关系;
接下来我们来详细的分析这两个过程。
1、收集关联的别名属性
收集注解这一步,将以当前注解的某个属性为根属性,根据链表结构向子注解递归,从子注解中获取全部与该属性相关的注解:
1 | private void collectAliases(List<Method> aliases) { |
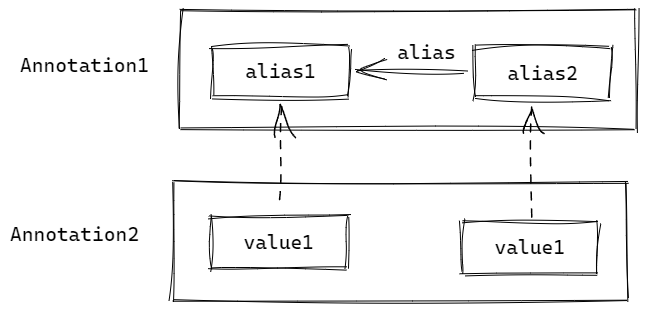
举个例子,假如我们现在有如下结构:
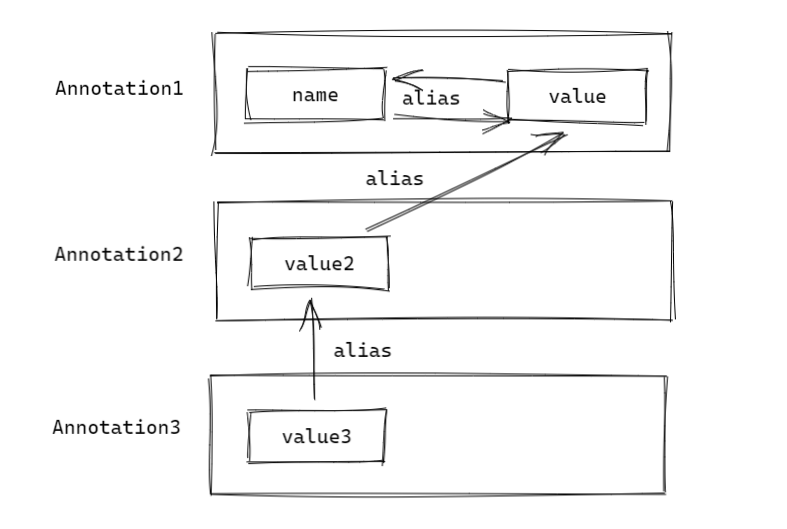
现在在 Annotation1 的 AnnotationTypeMapping 中,对它的 name 属性进行收集的时候,则最终将一路收集得到:
1 | [name, value, value2, value3] |
可见该方法会将全部关联注解对象中,在同一条别名链上的注解属性全部找出来。
2、处理别名属性
处理关联属性这做了三件事:
- 如果属性关联的这一组别名中,有一个别名属性是来自于 root 的,则直接无条件使用来自 root 的别名属性覆盖当前属性;
- 使用
MirrorSet解析并记录彼此之间具有关系的属性,然后根据一些规则从中选出唯一一个有效的属性作为它们的代表; - 使用通过
MirrorSet获得的代表属性替换所有关联属性,并记录该属性从哪一个注解的哪一个属性中取值;
1 | private void processAliases(int attributeIndex, List<Method> aliases) { |
其中,关于:
1 | int[] resolvedMirrors = mapping.mirrorSets.resolve(null, mapping.annotation, ReflectionUtils::invokeMethod) |
我们会在后续分析,这里我们举个例子说明一下上述过程:
一切开始前,我们从 Annotation1 向 Annotation3 遍历,此时我们处理 Annotation1 的属性 value1 :
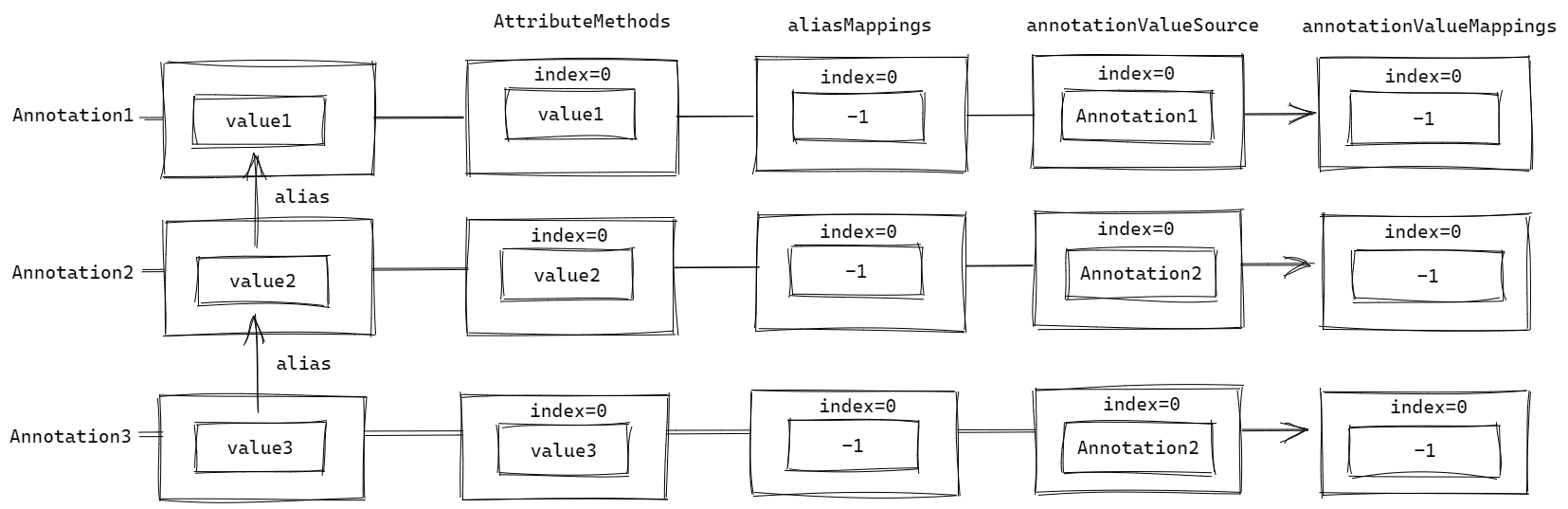
当调用 processAliases 后:
- 由于别名链上非根属性在根注解
Annotation3中都不存在,别名不动,此时三个注解的aliasMappings都不变; - 别名链上的三个属性
value1、value2和value3经过MirrorSet处理后,发现value3是优先级最高的,因而把它们的annotationValueSource、annotationValueMappings都分别更新为Annotation3和Annotation3.value3的下标;
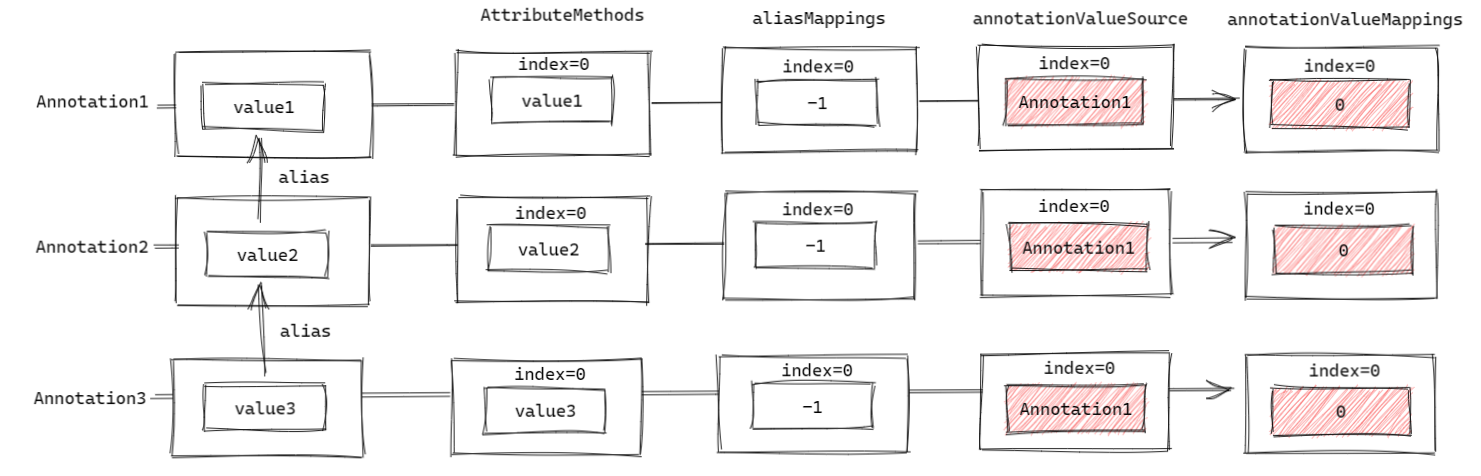
这样处理后,当调用 Annotation1.value1 方法时:
- 先从
AnnotationAttributes中获得value1的下标0; - 确认
annotationValueMapping[0]对应位置是否为-1,不是则说明有映射关系; - 最后从
annotationValueSource[0]位置取出Annotation1对应的AnnotationTypeMapping,再从annotationValueMappings[0]的位置取出0; - 从
Annotation1对应的AnnotationTypeMapping中找到下标0对应的方法value3,然后调用并返回值;
这样就是完成了映射过程。
3、别名属性关系的构建
现在我们回头看 AnnotationTypeMapping.processAliases 方法中的两个关于 MirrorSet 的操作:
1 | private void processAliases(int attributeIndex, List<Method> aliases) { |
从上文我们可知,MirrorSet 用于从一组存在直接或间接别名关系的不同注解属性中,确认唯一有效的属性。关于这个唯一有效属性,举个例子,比如现在有 A、B、C 多个属性互为别名,则最终取值的时候,只能有一个属性的值是有效值,这个值将被同步到所有的别名属性中,如果 A 是唯一有效属性,则通过 A、B、C 取到的值都会来自 A。
在这之前,需要先简单了解一下 MirrorSets ,和 AnnotationTypeMappings 以及 MergedAnnotations 的设计一样,Spring 同样以 MirrorSets 作为 MirrorSet 的聚合对象。
先简单看看 MirrorSet 的数据结构:
1 | class MirrorSets { |
MirrorSets 在内部维护了两个数组,分别是用于存放在不同属性间共享的 MirrorSet 实例的 mirrorSets,以及与 AnnotationAttributes 中属性一一对应的,用于存放该属性对应的 MirrorSet 实例,前者用于遍历,后者用于根据属性的索引下标查询关联属性。
当调用 MirrorSets.updateFrom 方法时:
1 | void updateFrom(Collection<Method> aliases) { |
接着我们再看看 MirrorSet.update :
1 | class MirrorSet { |
简单的来说,就是遍历 MirrorSets.assigned 数组,看看哪些属性是共享当前 MirrorSet 实例的,然后把注解属性的下标给记录到 indexes 中。
举个例子,我们现在有一个注解,他的两个属性构成了互为别名的关系,现在对其中一个进行处理,则有如下情况:
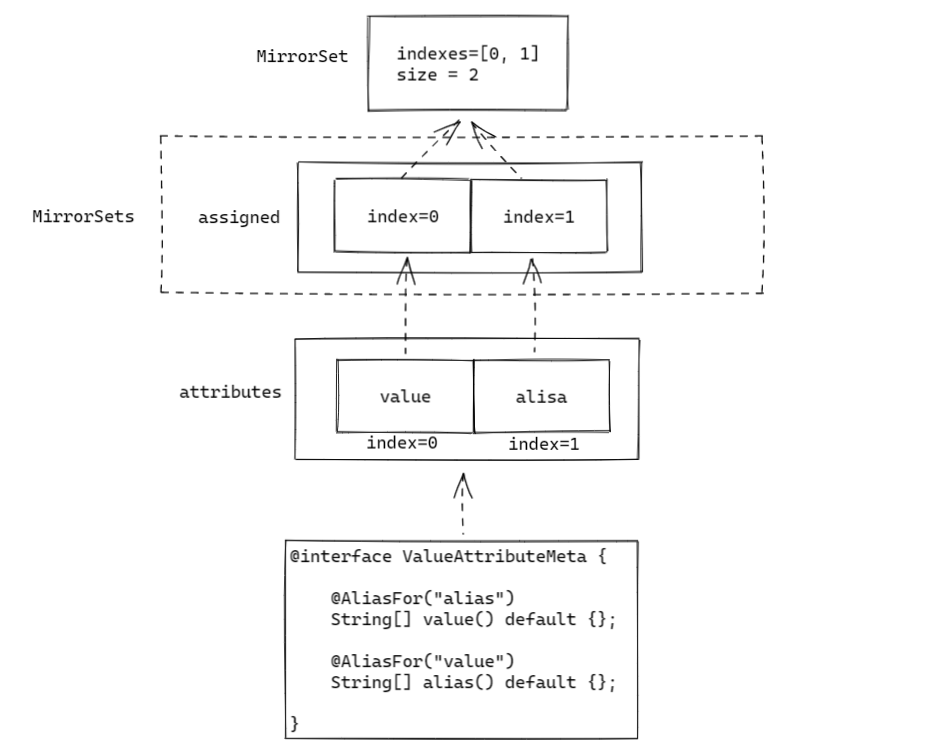
value和alias属性在AnnotationAttributes中对应的下标分别是0和1;- 处理时,由于
value和alias处于同一条别名链,因此MirrorSets.updateFrom调用时会同时传入这两者; - 由于
value和alias都在ValueAttributeMeta这注解中存在,因此MirrorSets会分别为它们在assigned数组中对应的下标位置放入MirrorSet实例; - 接着,调用
MirrorSet.update时,发现assigned[0]与assigned[1]共享一个MirrorSet实例,说明两者是有联系的,然后就在该MirrorSet实例中的indexes数组记录这两个位置0和1;
4、别名属性唯一值的确认
接上文,当 MirrorSets.updateFrom 调用完毕后,同一注解内的不同属性该关联的实际上都关联上了,接着会调用 MirrorSets.resolve 为这些关联的属性都找到唯一确认的最终属性:
1 | int[] resolve( Object source, Object annotation, ValueExtractor valueExtractor) { |
而 MirrorSet.resolve 则是根据一些条件确认一组关联属性中的唯一有效属性的下标:
1 | <A> int resolve( Object source, A annotation, ValueExtractor valueExtractor) { |
这里的逻辑应该是比较清晰的,首先,如果同一个注解内存在多个互为别名的属性,则需要有一个唯一有效的最终属性,所有互为别名的属性应当以这个最终属性的值为准。
对应到代码中,则就是通过遍历 MirrorSet 中互为别名的字段,然后根据下述规则找到最终属性:
- 如果所有属性都只有默认值,则离根注解最近的属性最为最终属性;
- 如果所有属性中存在属性有非默认值,则该属性就作为默认属性,若出现多个有非默认值的属性,则直接报错;
然后返回这个最终属性的下标。
我们举个例子,假如现在有 A,B,C,D,E 五个属性,其中 A 和 B、C 和 D 互为别名,则经过 MirrorSets#resolve 方法最终得到的 resolvedMirrors 如下图:
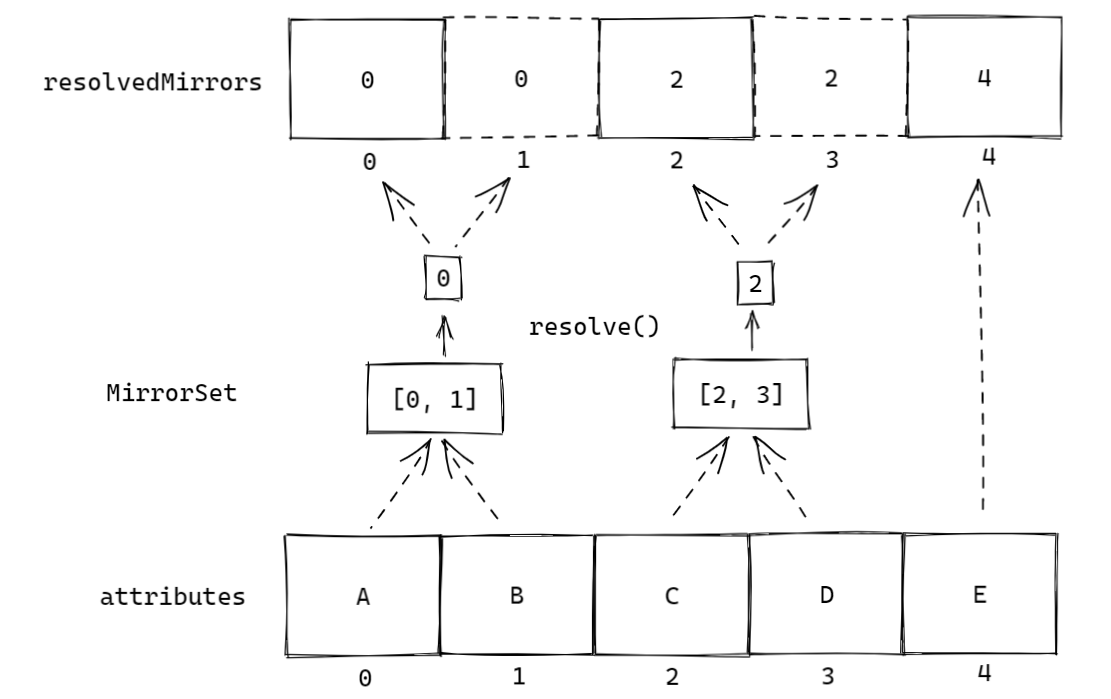
把resolvedMirrors翻译一下,就是 A 和 B 取值时都取 A 的值,C 和 D 取值时都取 C 的值,而 E 取值照样取 E 的值。
4、多级别名
看到这里,我们对别名机制大概有个轮廓了,任何关联的注解中,只要通过 @AliasFor 能直接或者间接联系上,那它们就能构成别名。
因此,哪怕存在这样的结构:
1 |
|
当使用 @Annotation2 时,只要对 value1 或者 value2 进行赋值,最终都能从两个注解的各两个属性中拿到一样的值:
五、映射属性覆盖
现在,通过 annotationValueMappings,annotationValueSource以及 AttributeMethods这三个成员变量,任何一个使用@AliasFor 注解配置了别名的属性都可以找到真正对应的值。
不过在 Spring 中,还支持一种默认的属性覆盖机制,即当父子注解都存在一个名称与类型皆相同的属性时,子注解的属性值将会覆盖父注解的属性值。
在 AnnotationTypeMapping 的构造函数中,实现该功能的代码共分为两步:
1 | // 为元注解与根注解同名的属性强制设置别名 |
1、根注解覆盖元注解
addConventionMappings 用于实现根注解覆盖所有其元注解中同名同类型属性的逻辑:
1 | private void addConventionMappings() { |
这一步将遍历当前注解中的属性,然后判断是否在根注解中存在同名属性,若存则直接将 conventionMappings 中对应下标的位置设置为根注解对应属性的下标。
2、子注解覆盖父注解
addConventionAnnotationValues 用于实现子注解覆盖父注解中同名同类型属性的逻辑:
1 | private void addConventionAnnotationValues() { |
它大概干了这些事:
- 若自注解中存在非
value同名字段,则将与当前属性对应位置的annotationValueSource和annotationValueMappings设置为该子注解和该注解中同名属性的方法下标; - 若子注解的子注解中仍然存在同名注解,则选择一个离根注解最近的子注解,重复上述过程;
- 重复上述两步直到全部子注解递归完毕;
总结
回滚整个流程,我们了解了 Spring 中元注解的解析过程,与注解的属性覆盖与别名机制的实现。
当我们通过 MergedAnnotations 去从 AnnotatedElement 获取注解的时候,会有专门的 AnnotationProcessor ——比如 MergedAnnotationFinder——去把指定类型的注解上的全部元注解解析为 AnnotationTypeMapping,然后 AnnotationTypeMapping 在把一个一个的元注解对象转为 AnnotationTypeMapping,让他们形成类似链表的结构,从而维持父子注解间层次关系。
而当 AnnotationTypeMapping 在创建时,会递归解析 AnnotationTypeMapping 链表结构上的全部节点,然后解析他们的属性,让通过 @AliasFor 构成别名关系的属性在各个注解中以 MirrorSet 的形式存在,从实现别名机制。
并且,在完成别名映射后,AnnotationTypeMapping 还会再次递归解析AnnotationTypeMapping 链表结构上的全部节点的属性,让子注解中与父注解具有相同名称、类型的非 "value" 属性覆盖父注解中的属性。