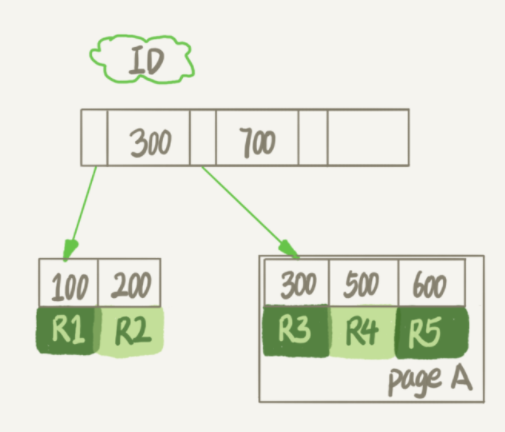
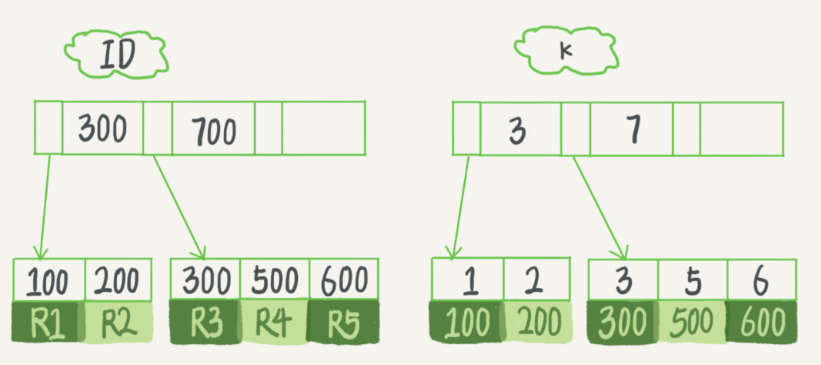
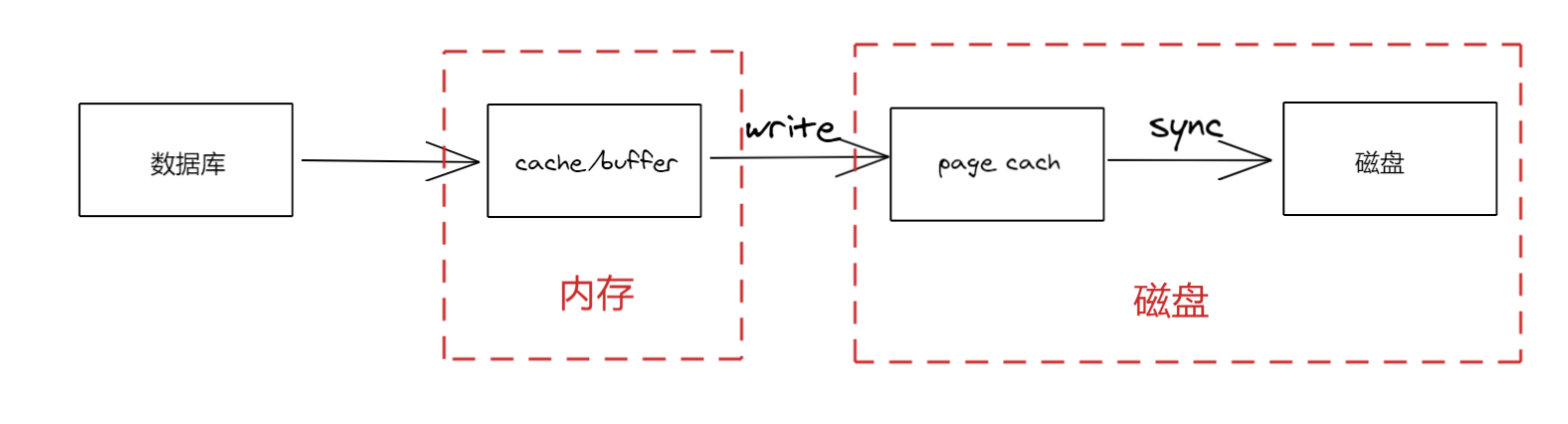
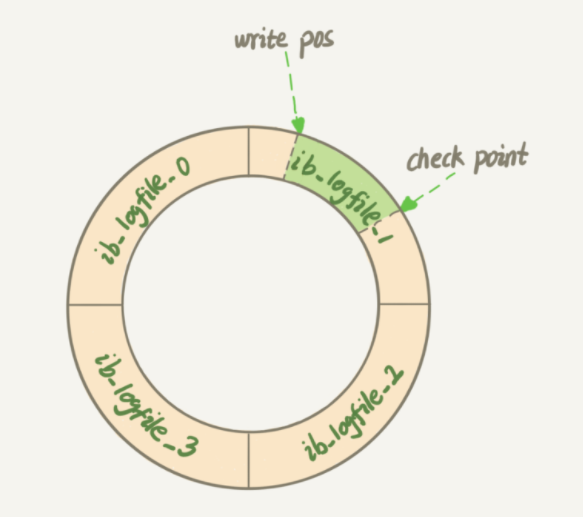
此文为极客时间:MySQL实战45讲的 6、7、20 节锁相关部分的总结
一、全局锁
1.概述
全局锁就是对整个数据库实例加锁。通过使用 Flush tables with read lock(FTWRL)语句加锁,此后整个库都会处于只读状态,这时,其他线程的数据定义语句(DDL),数据操作语句(DML)以及更新类事务的提交语句都会被阻塞。
也就是说,加了全局锁以后,其他线程不能对数据增删改,也不能对表增删改。
另外值得一提的是,在此之前,数据库会等待 FTWRL 操作前的所有读写操作完成,事务提交完毕;并且把脏页的数据从缓存刷入磁盘,保证数据的一致性。
全局锁的典型使用场景是对数据库进行整库备份。
2.全局锁的缺陷和解决方案
全局锁有以下问题:
- 如果你在主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆;
- 如果你在从库上备份,那么备份期间从库不能执行主库同步过来的 binlog,会导致主从延迟。