一、什么是平衡二叉树
1.概述
平衡二叉树(AVL树)是一种带有平衡条件的二叉搜索树。它的特性如下:
- AVL树的左右两个子树的高度差的绝对值不超过1
- AVL树的左右两个子树都是一棵平衡二叉树
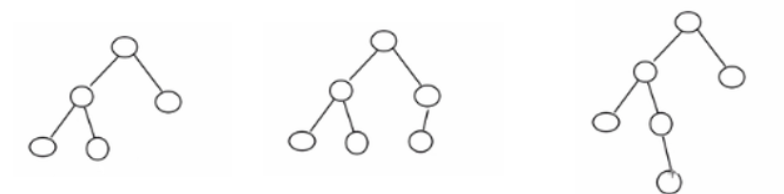
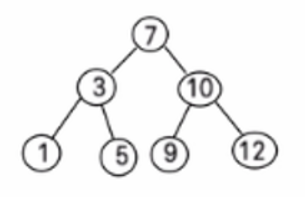
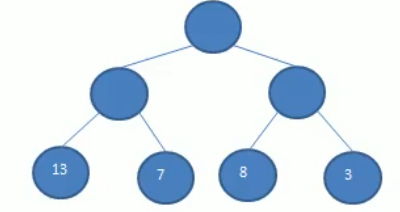
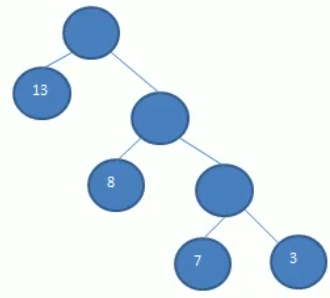
举个例子,如上图所示:
- 第一棵树左树高2,右树高1,差值为1,是一颗AVL树;
- 第二棵树左树高2,右树高2,差值为0,是一颗AVL树;
- 第三棵树左树高3,右树高1,差值为2,不是一颗AVL树;
红黑树就是一直AVL树。
2.为什么需要平衡二叉树
当我们使用二叉排序树的时候,当连续插入顺序的节点的时候就会出现问题。比如,我们插入{1,2,3,4,5}这样一个数组: